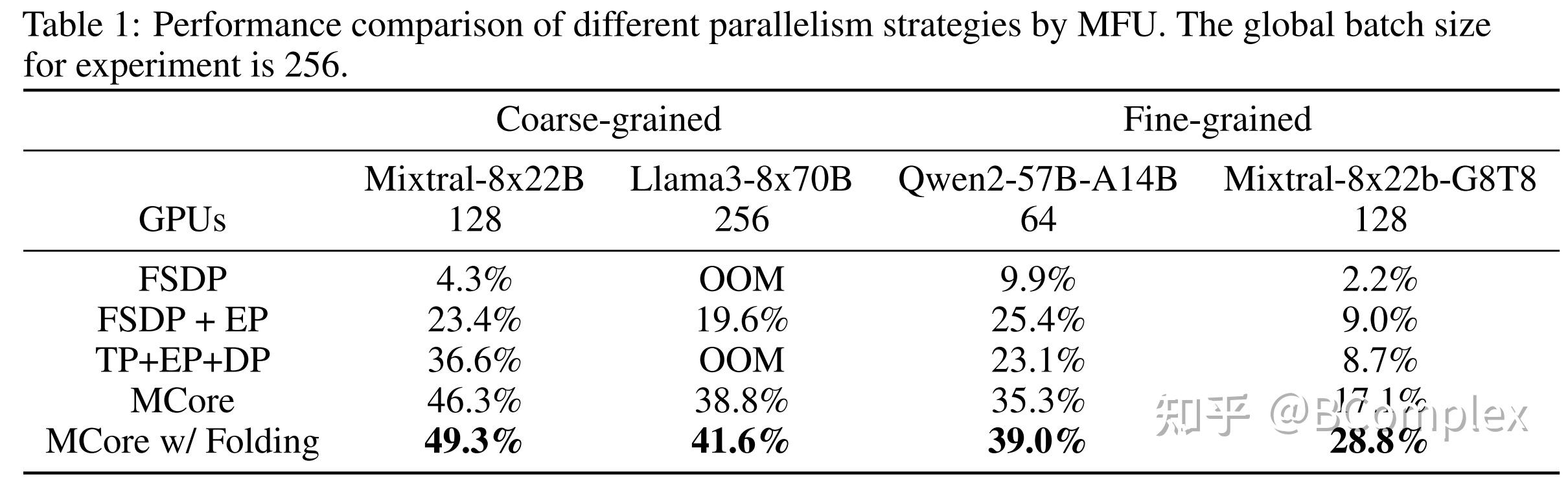
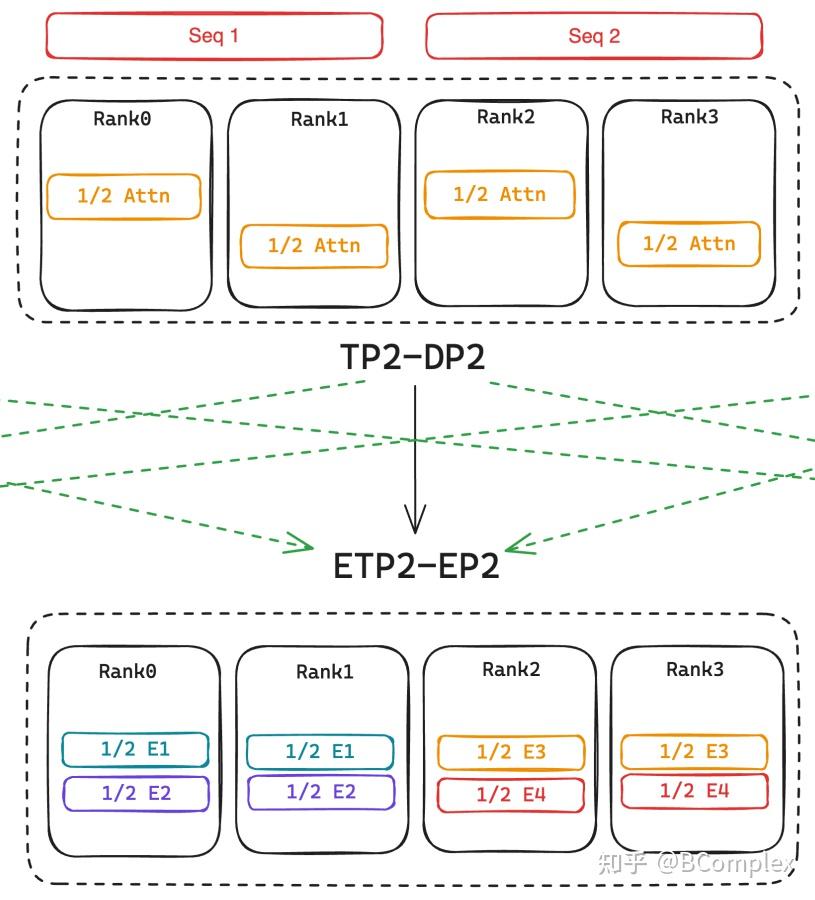
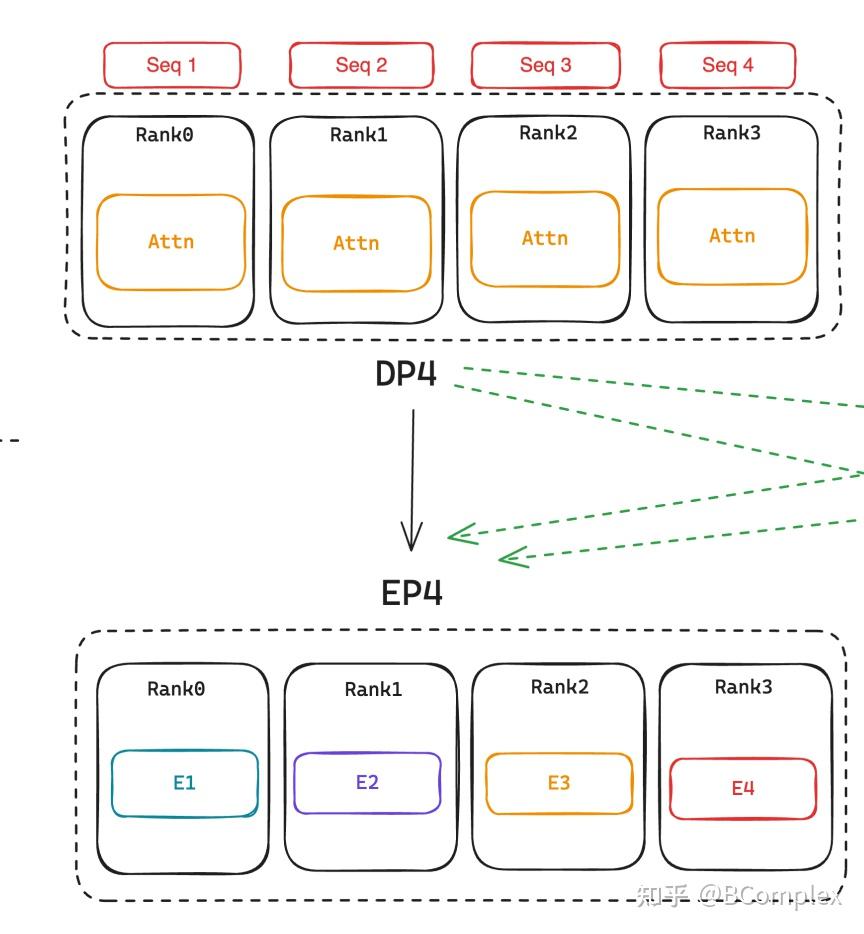
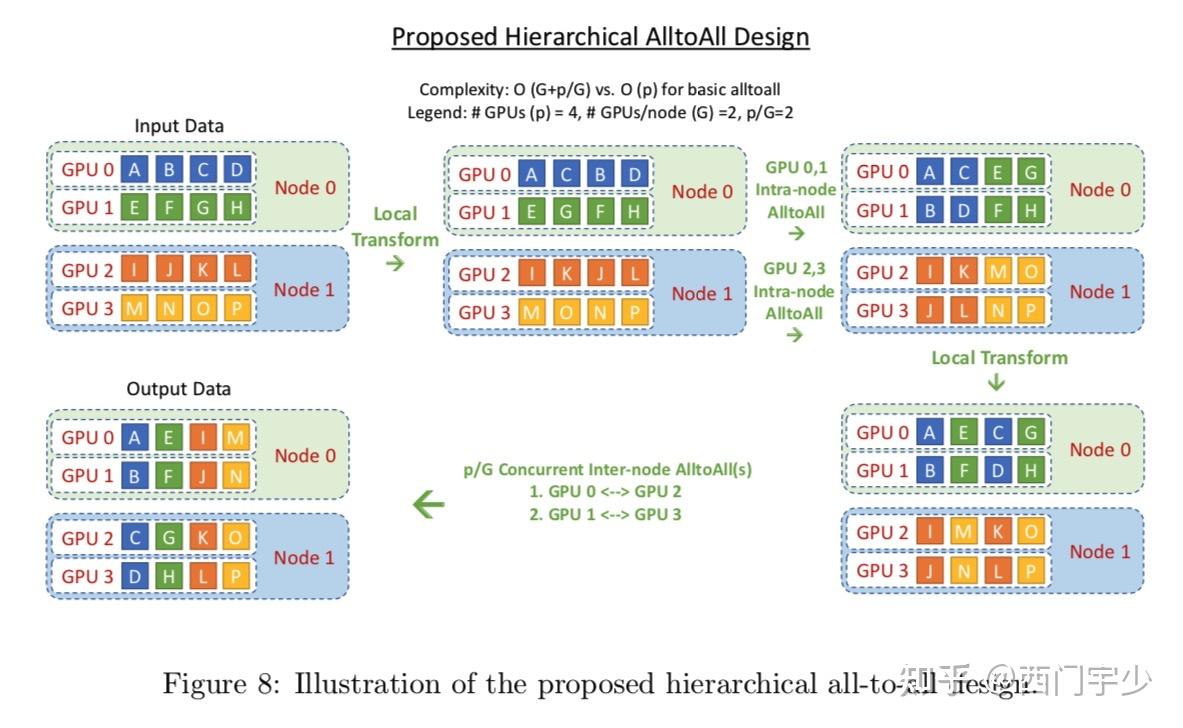
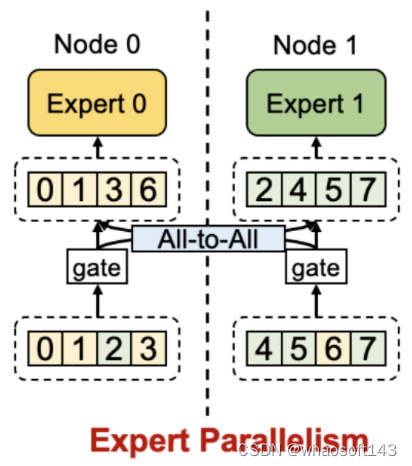
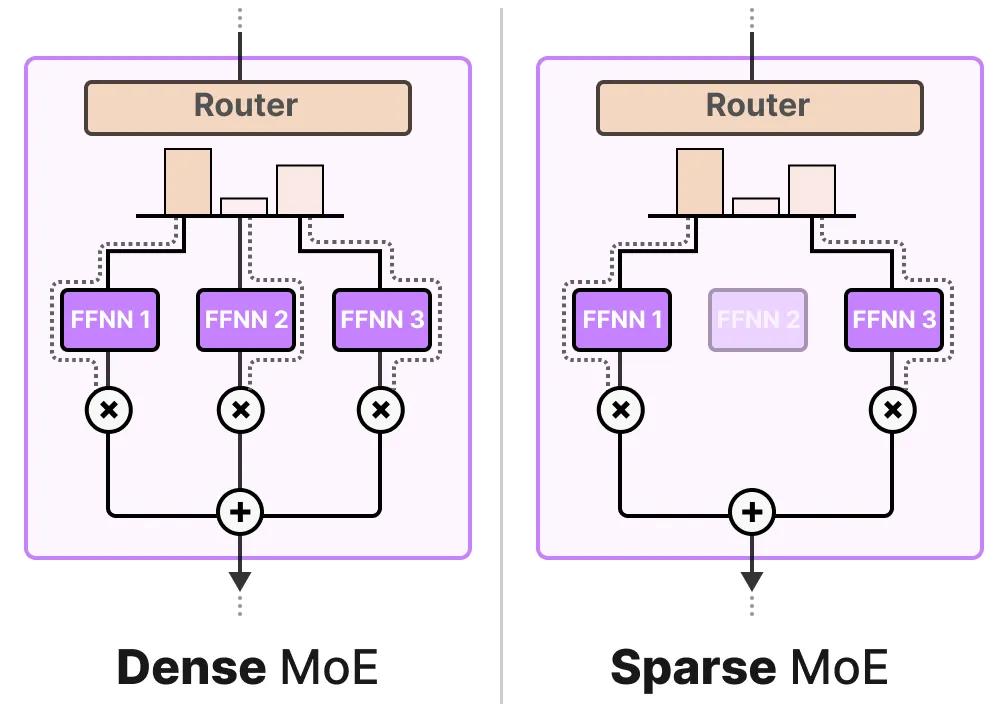
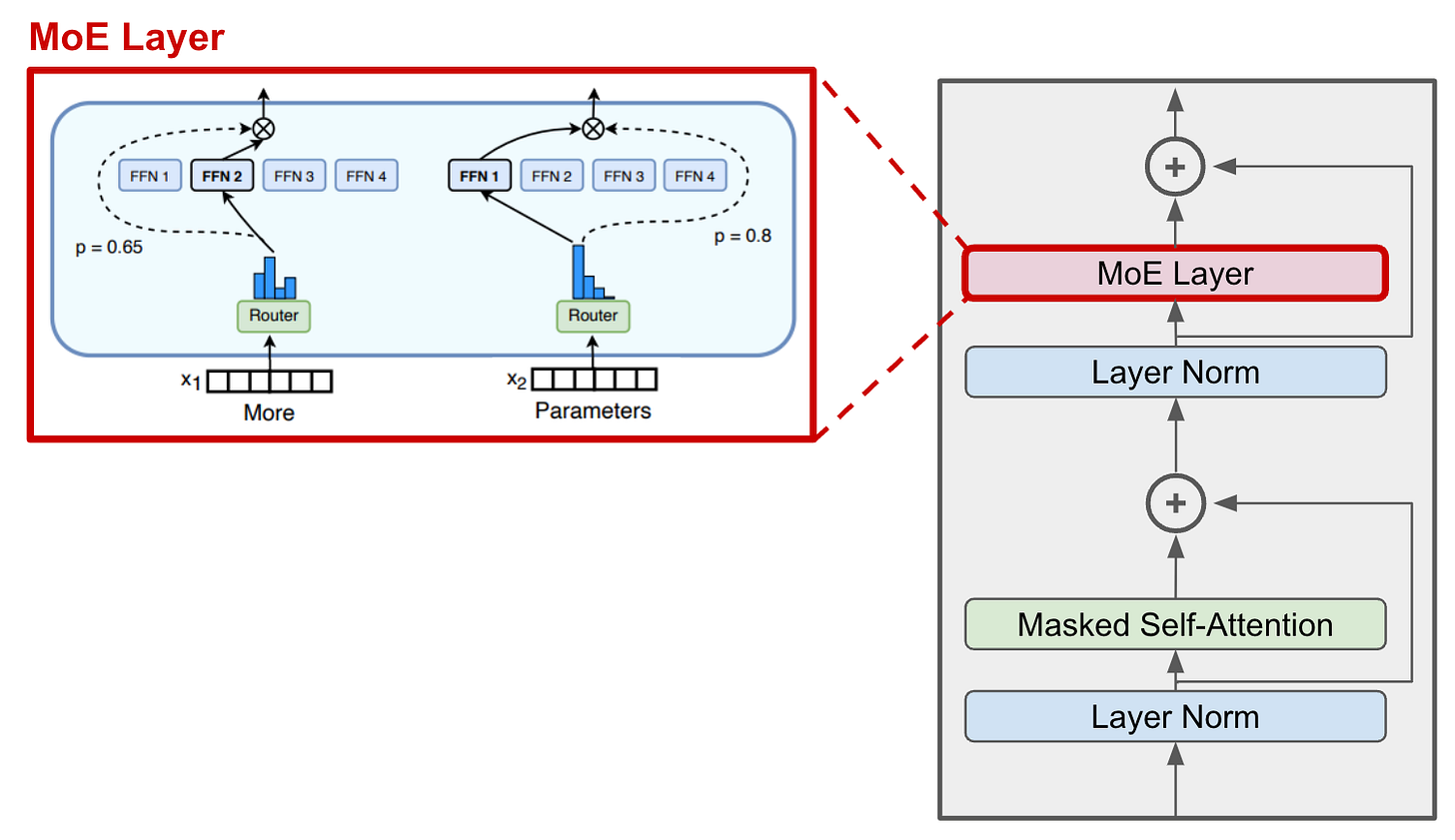
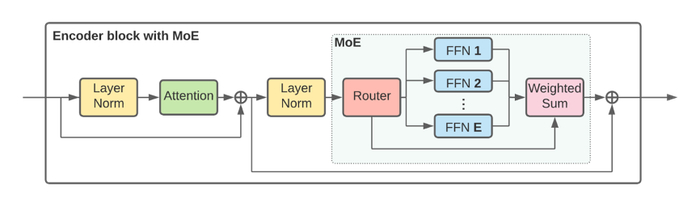
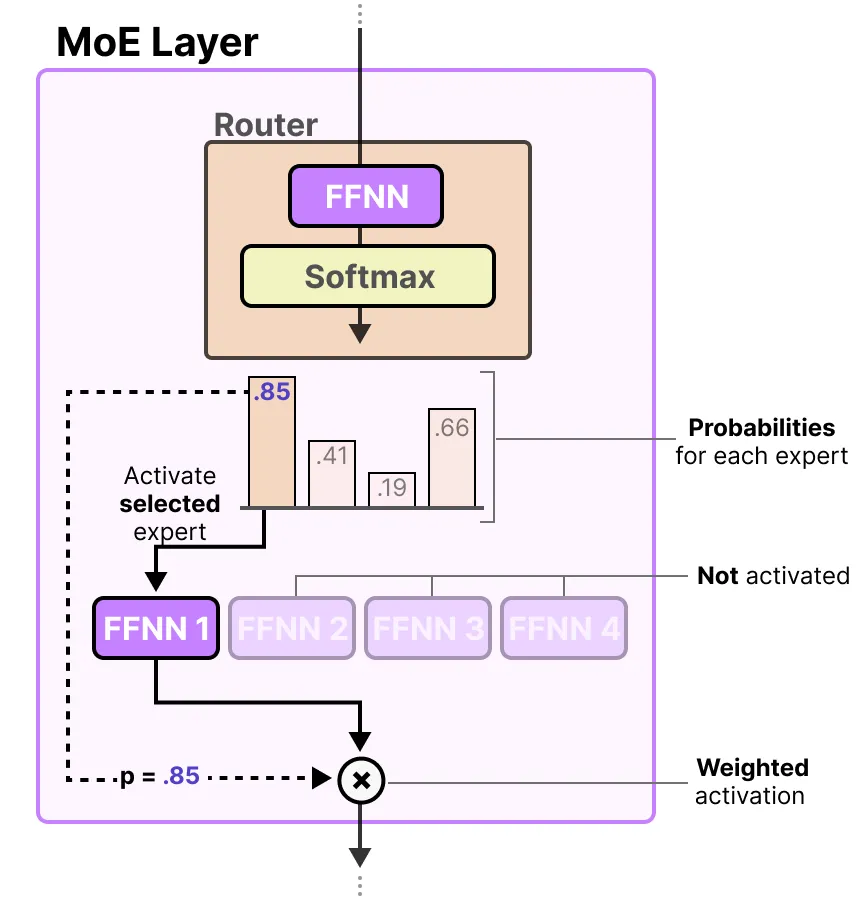
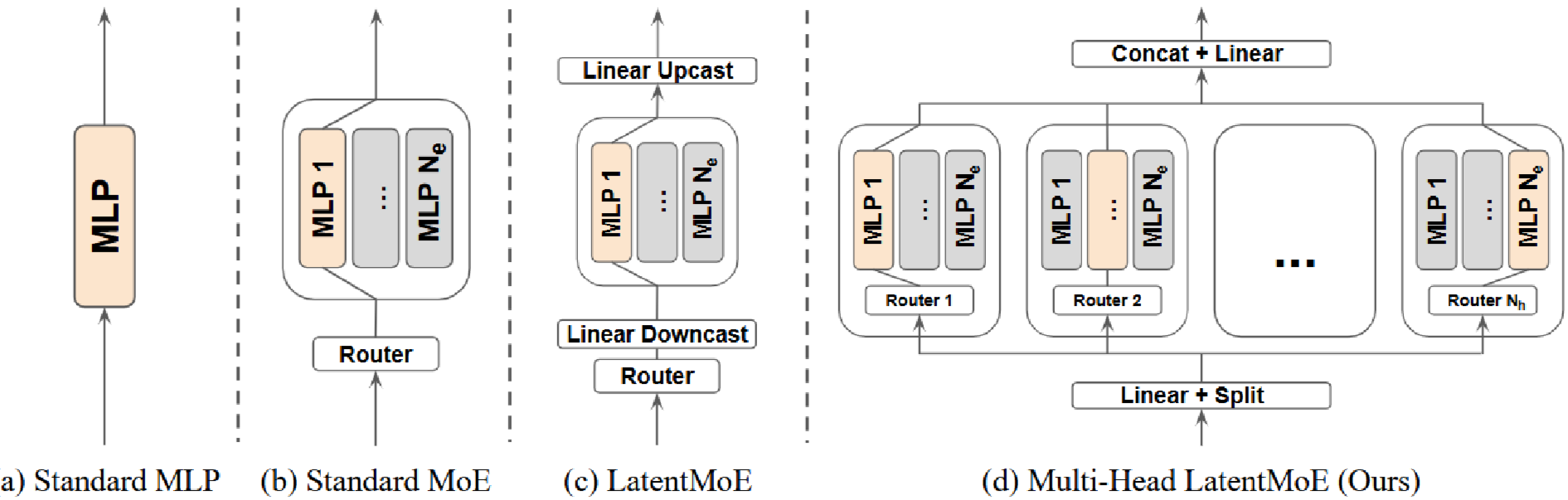
Showing 120 of 120on this page. Filters & sort apply to loaded results; URL updates for sharing.120 of 120 on this page
MoE Parallel Folding阅读笔记-Megatron-5D并行实践 - 知乎
MOE and MOR parallel between treatments | Download Scientific Diagram
MOE & MOA for Large Language Models | Towards Data Science
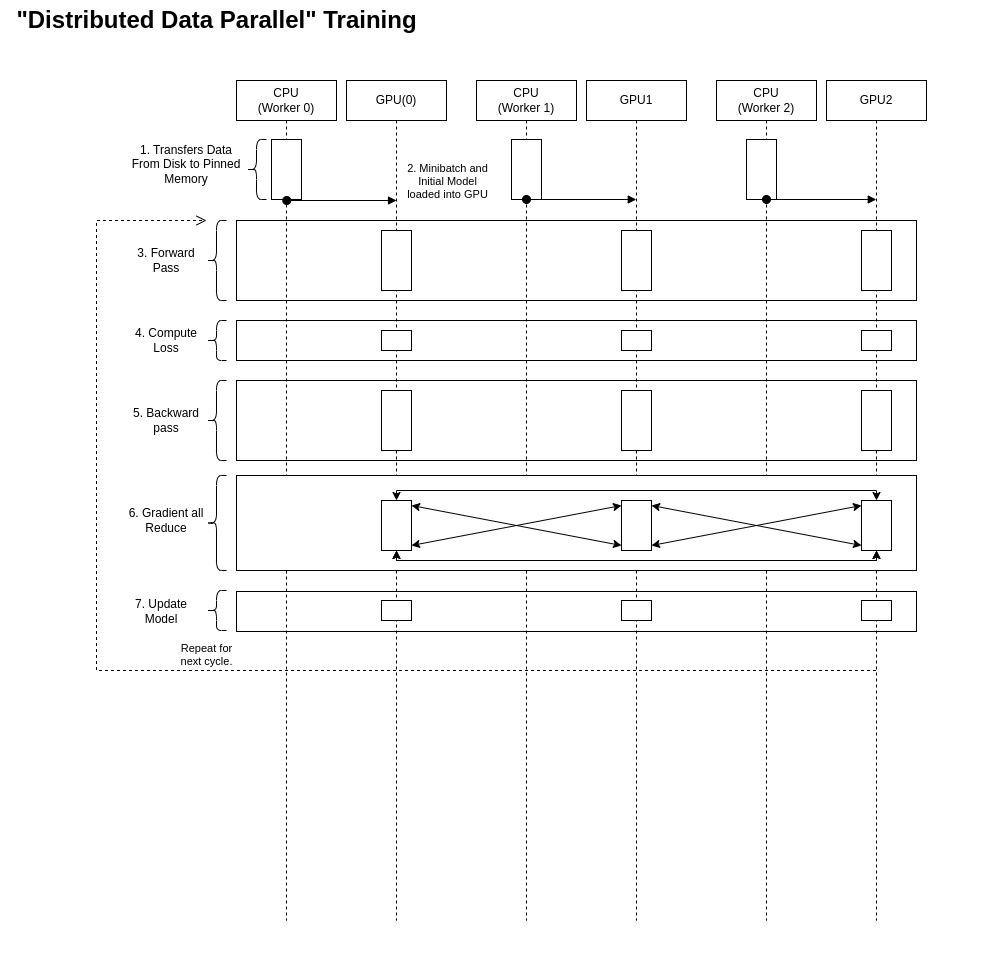
PyTorch Distributed Data Parallel (DDP) Training in Kaggle
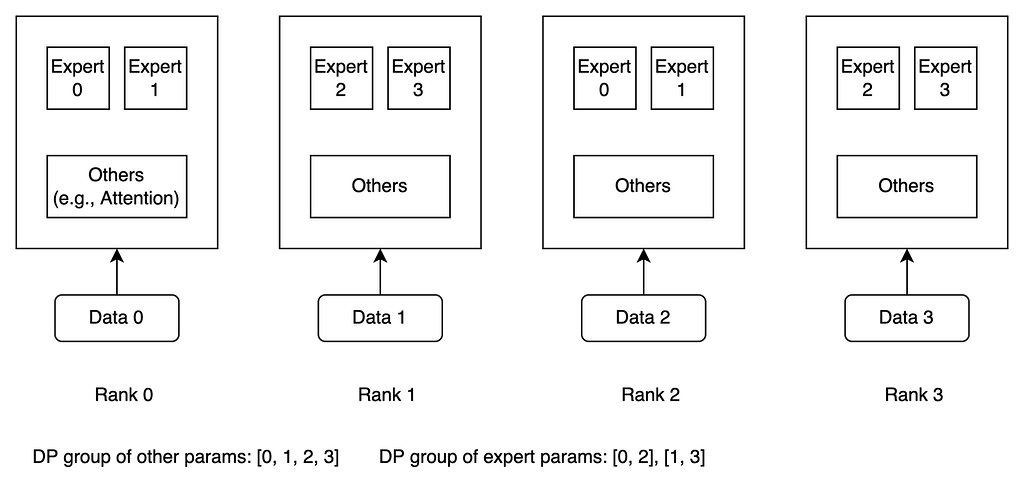
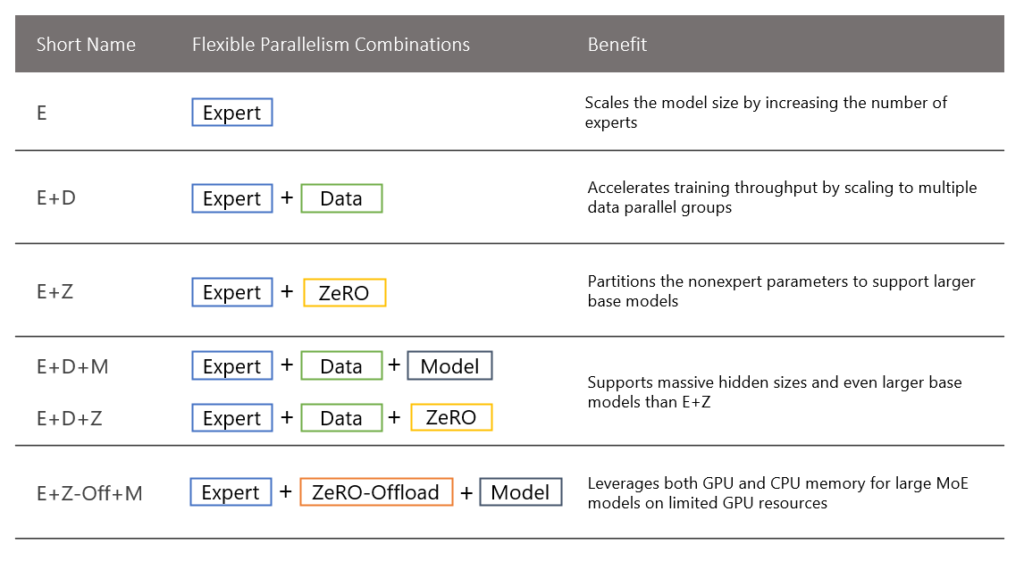
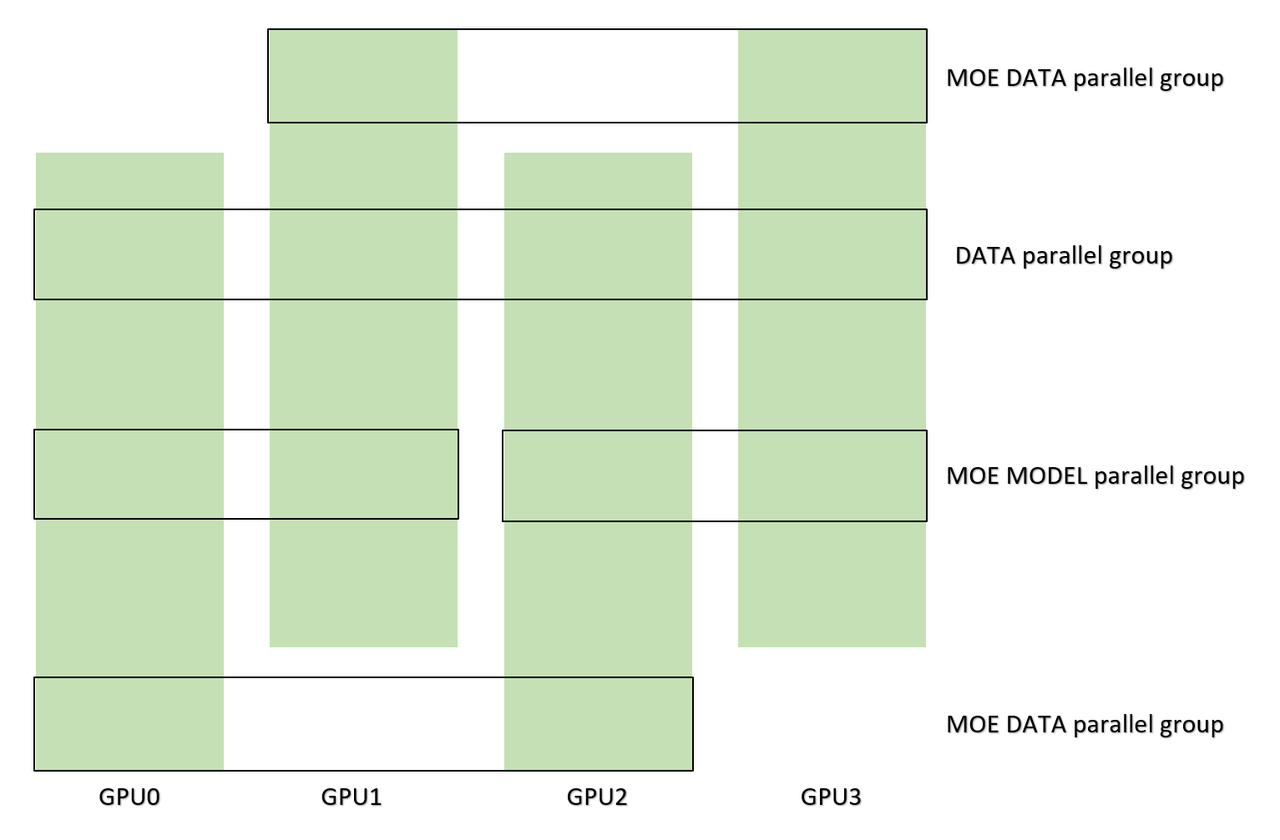
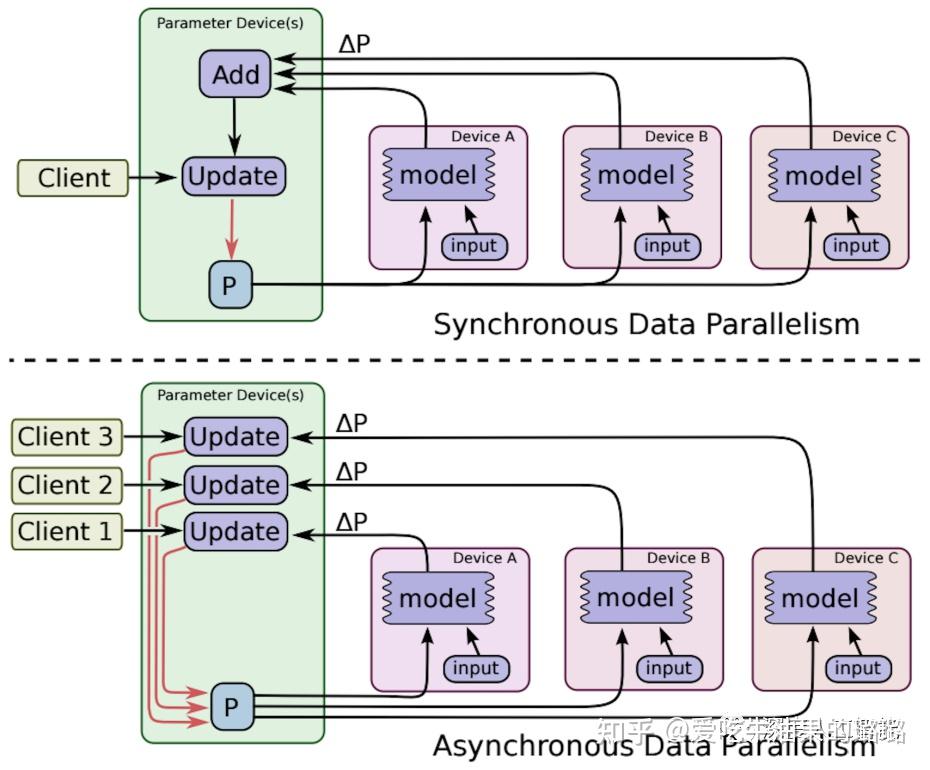
Integrating Expert and Data Parallelism in MoE
Histogram for MOE parallel to the grain. | Download Scientific Diagram
MOE parallel to grain from destructive tests [9]. | Download Table
Paper page - Speculative MoE: Communication Efficient Parallel MoE ...
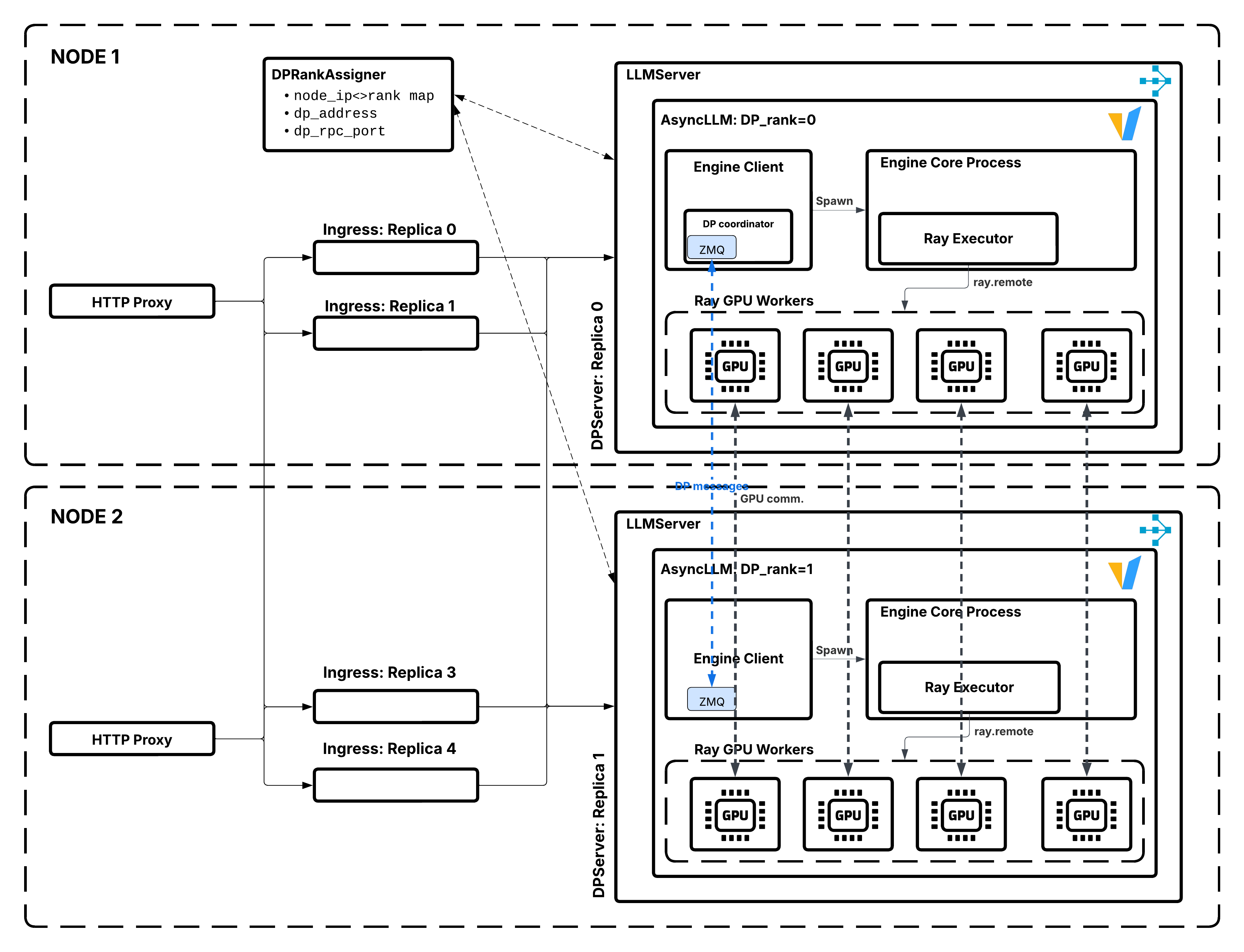
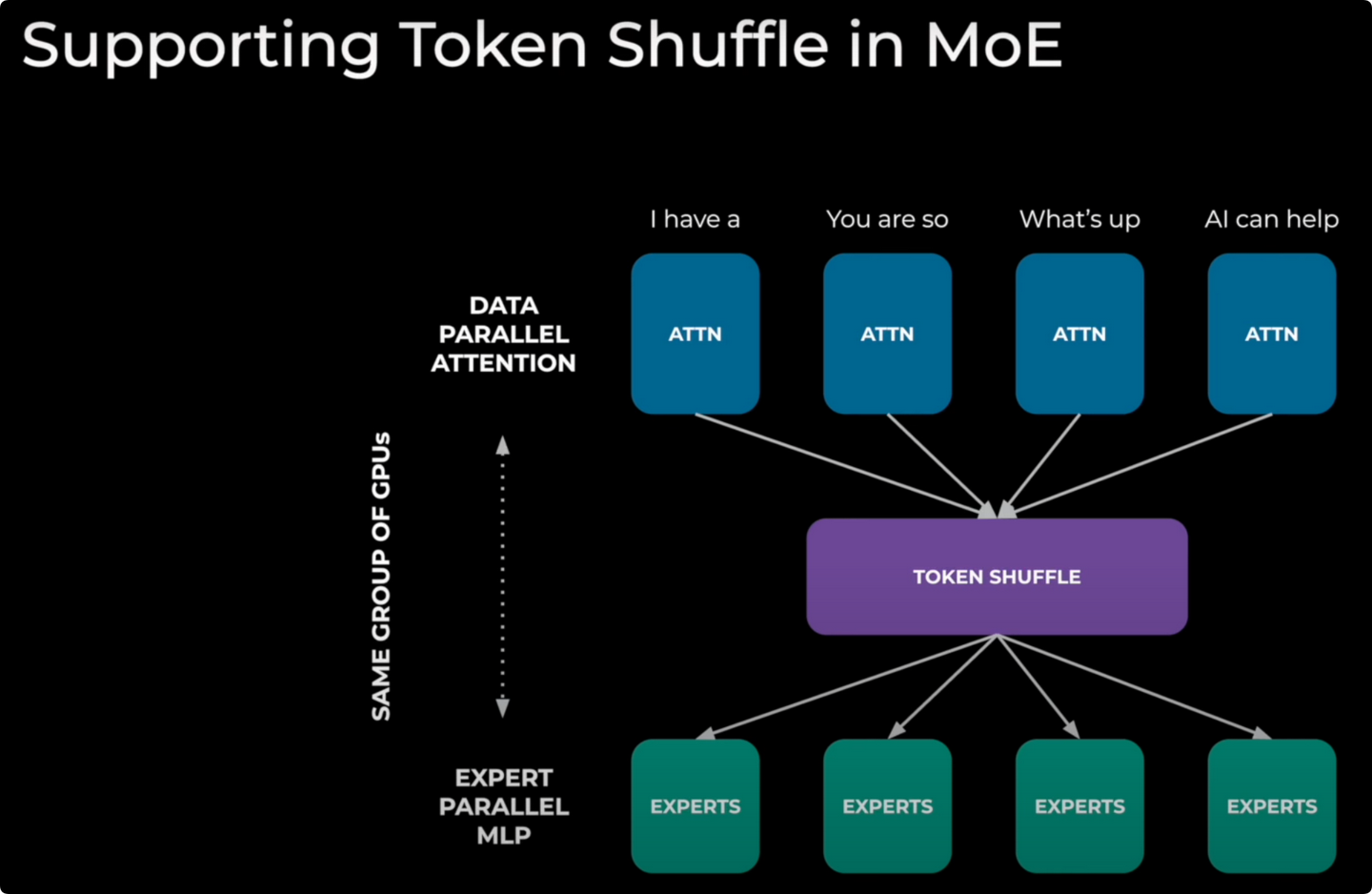
Data parallel attention — Ray 2.55.0
Architecture of an MoE prediction model for a single data point x i ...
(PDF) Speculative MoE: Communication Efficient Parallel MoE Inference ...
Distributed Data Parallel and Its Pytorch Example | 棒棒生
Speculative MoE: Communication Efficient Parallel MoE Inference with ...
[Usage]: How to do expert parallel on MoE model? · Issue #21054 · vllm ...
Proposed model (PSP) data mining in the portal of MOE | Download ...
MOE Database Viewer: Advanced Molecular and Data Visualization - CCG ...
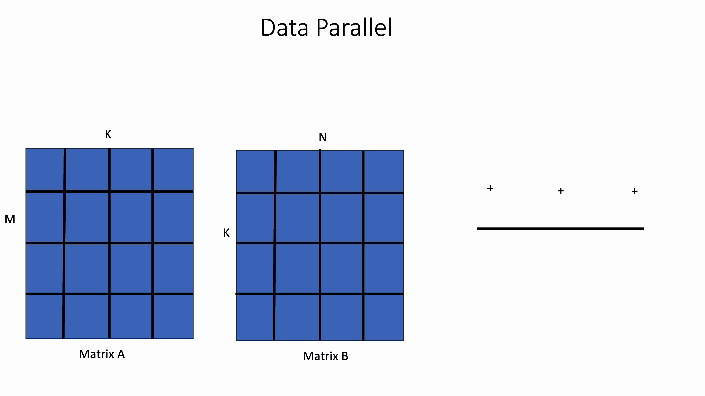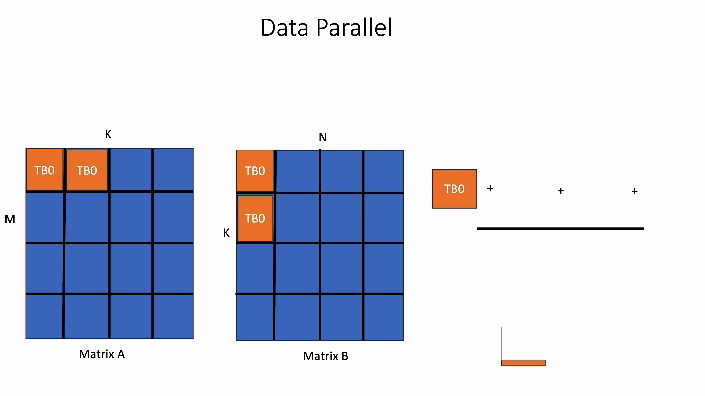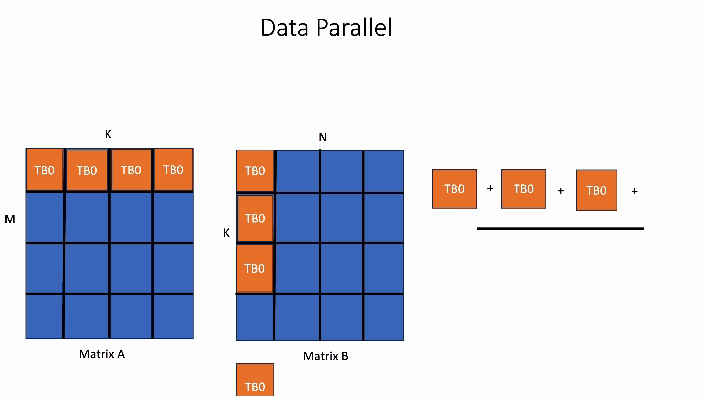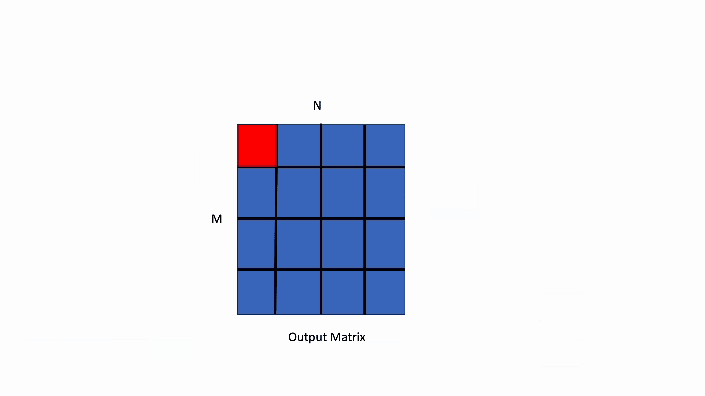
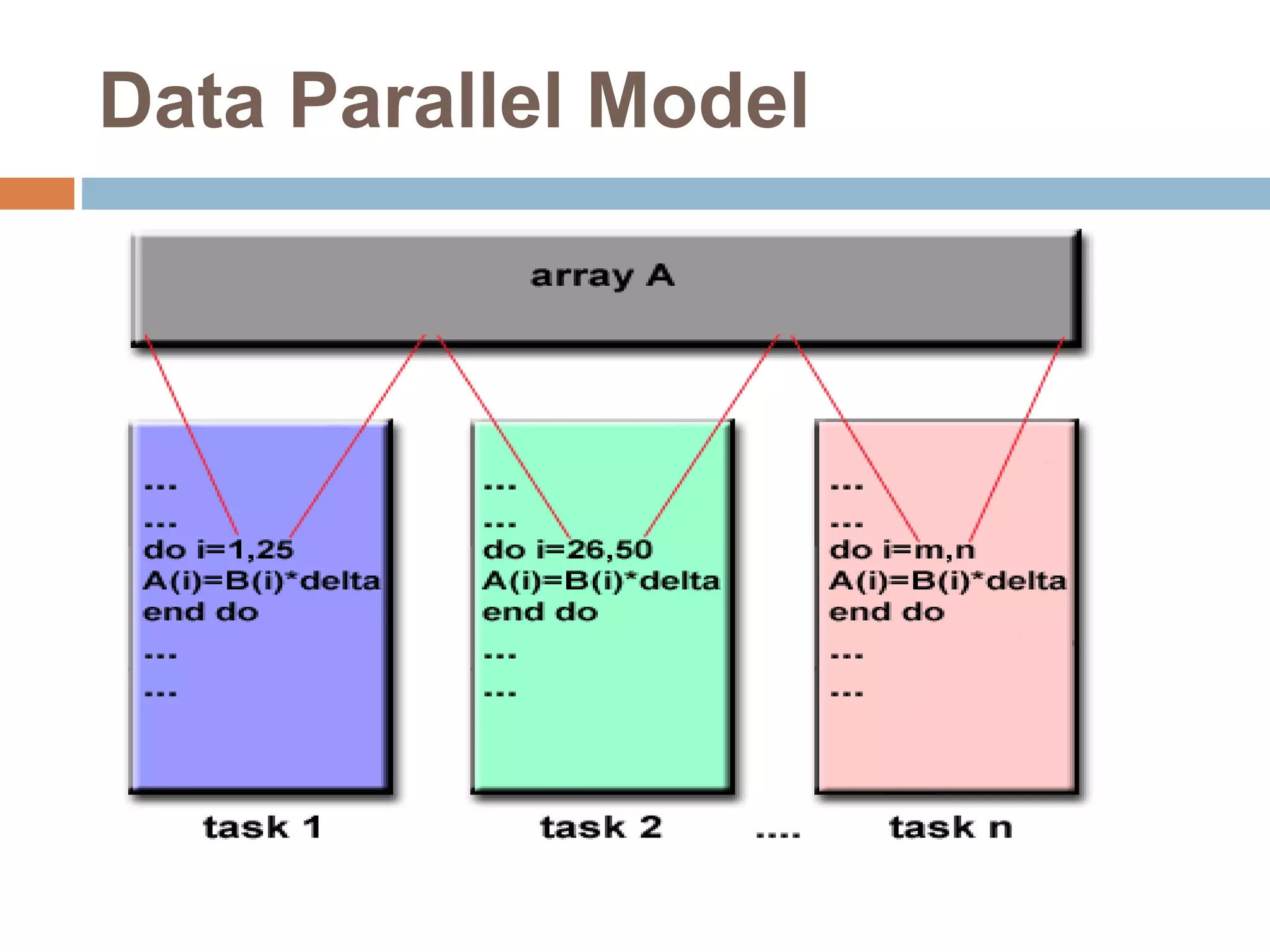
Data Parallel Algorithms - ppt download
The MOE parallel to the grain direction of gmelina OSBs on various ...
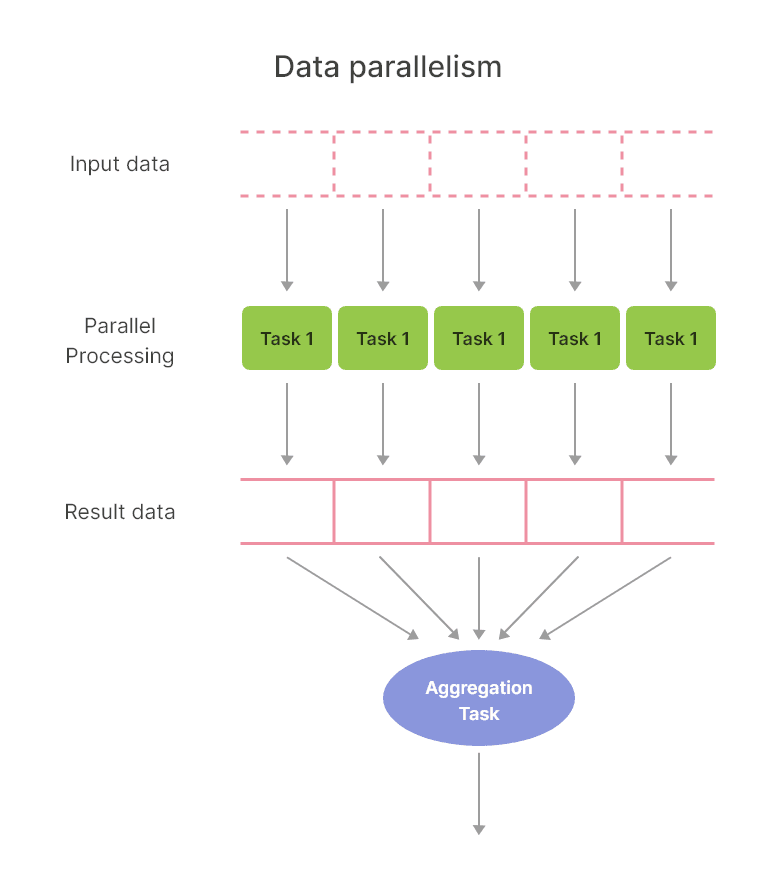
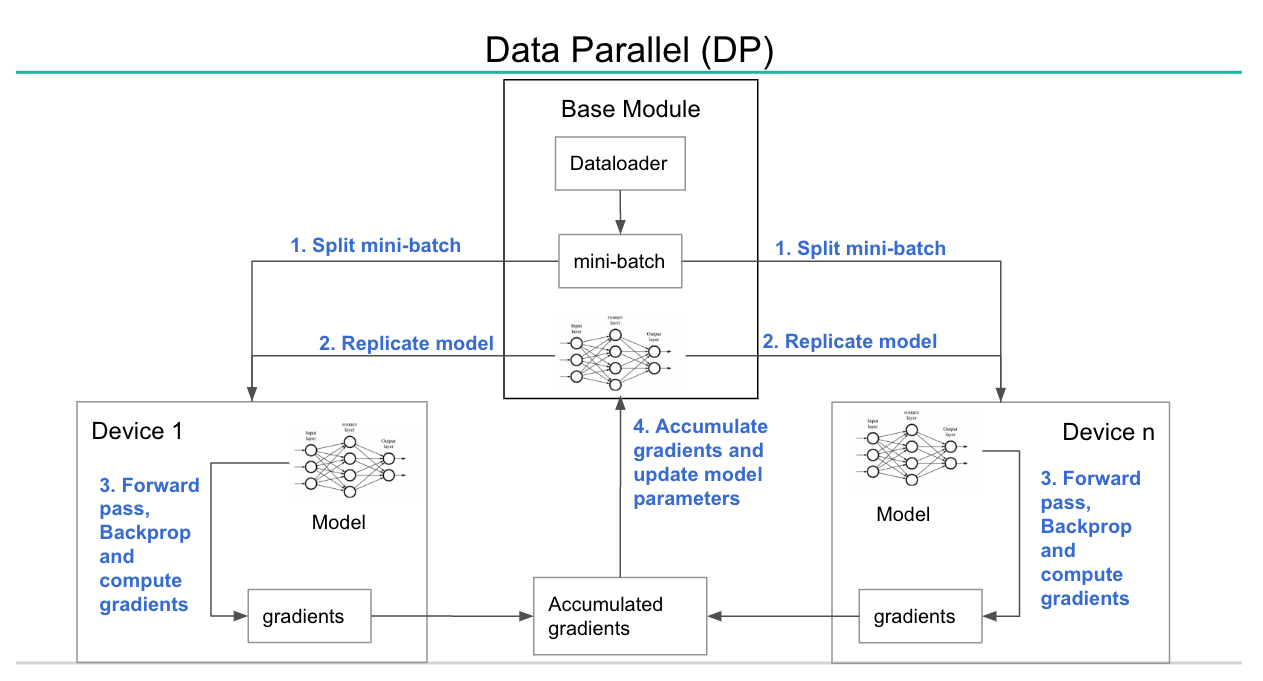
Part 1: A Brief Guide to the Data Parallel Algorithm | by The Machine ...
A Toolkit For The Implementation of Parallel Data Mining and Machine ...
MoE representation with C experts. Solid lines indicates direct data ...
ANOVA value of MOE in parallel direction to the grain | Download Table
(a) The value of MOE BOSB parallel and (b) perpendicular to the grain ...
[论文评述] Speculative MoE: Communication Efficient Parallel MoE Inference ...
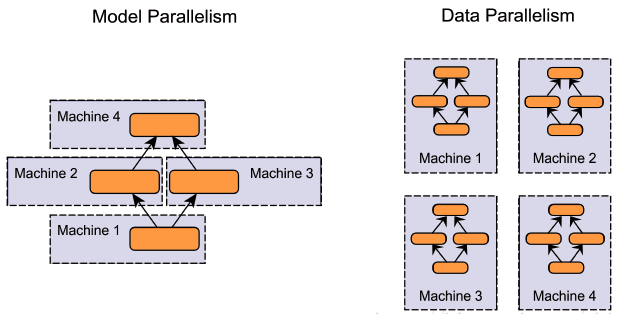
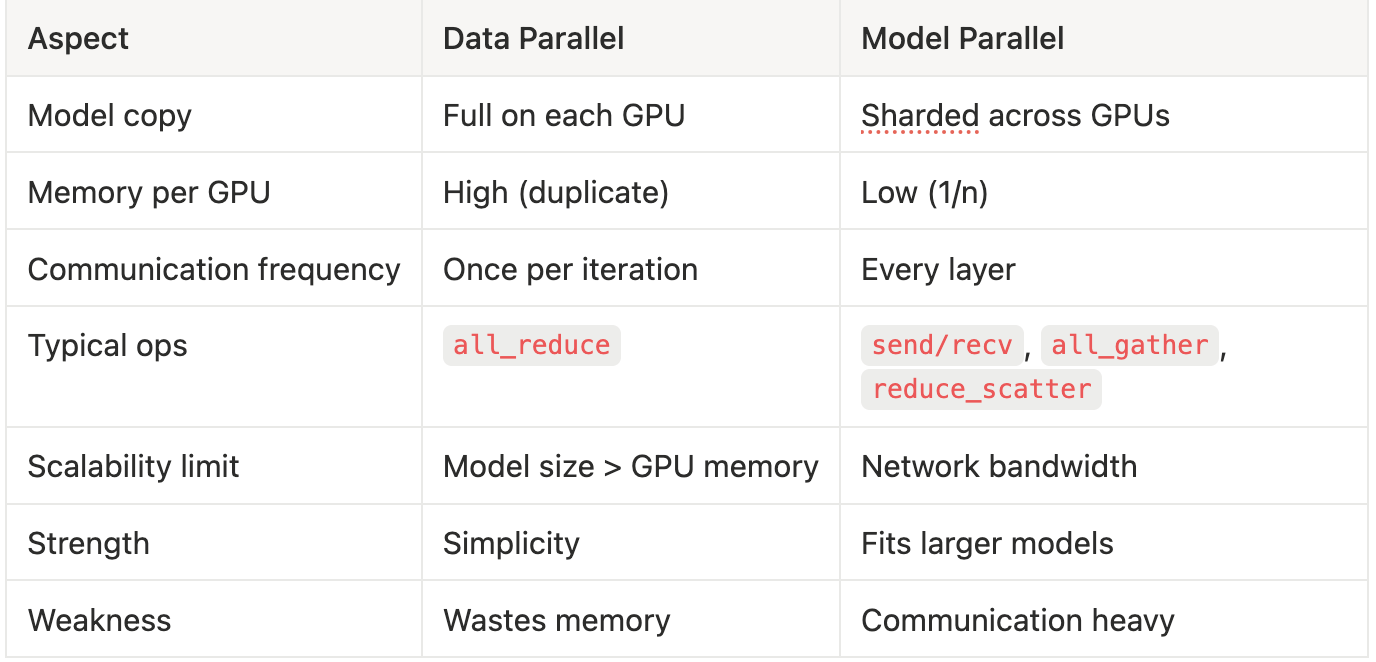
Part 1 — The Old World: Data vs Model Parallel
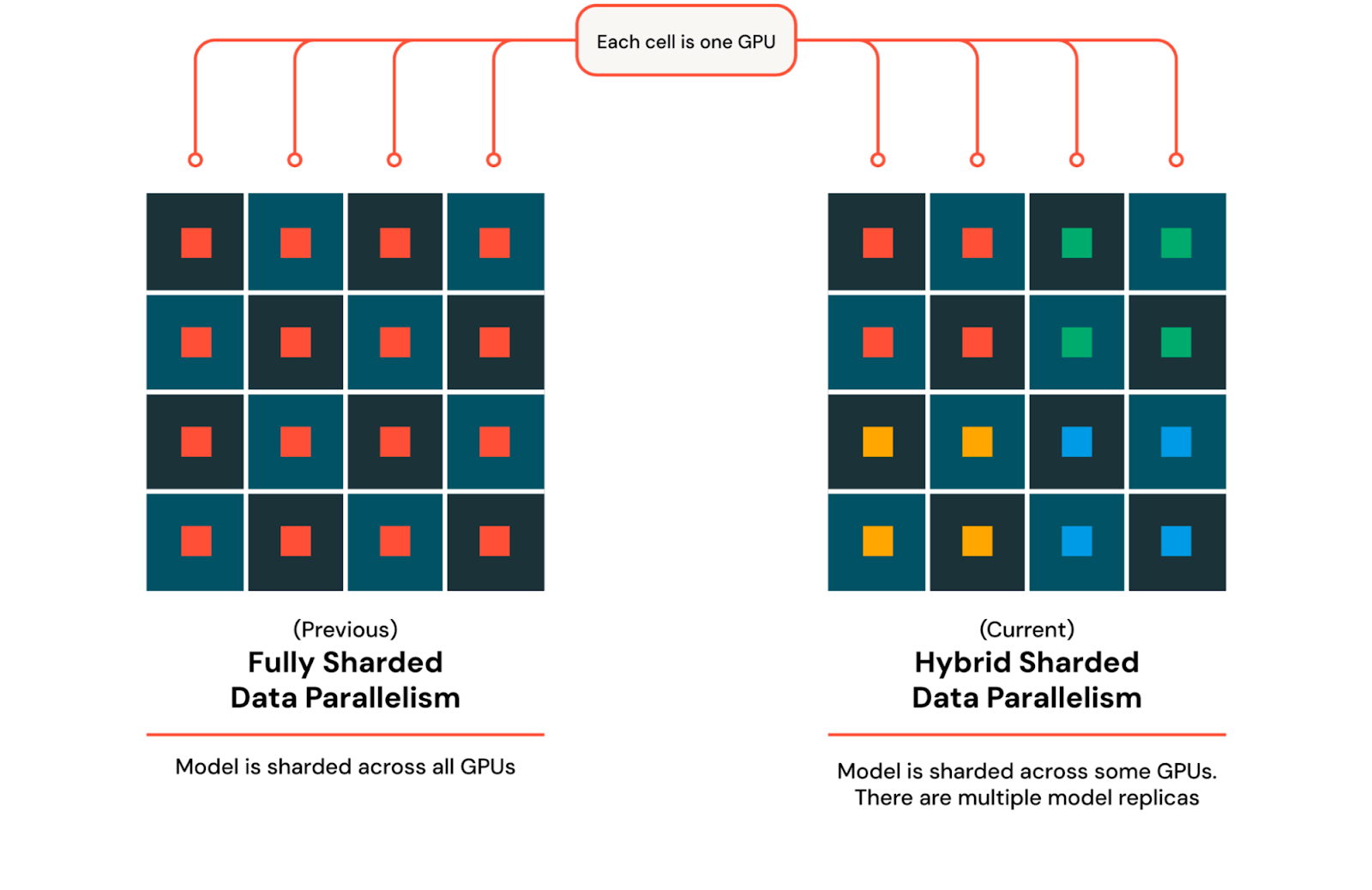
How to train Mixture-of-Experts (MoE) model with Fully Sharded Data ...
Enhanced MoE Parallelism, Open-source MoE Model Training Can Be 9 Times ...
GitHub - zms1999/SmartMoE: A MoE impl for PyTorch, [ATC'23] SmartMoE ...
Accelerating MoE model inference with Locality-Aware Kernel Design ...
[2304.11414] Pipeline MoE: A Flexible MoE Implementation with Pipeline ...
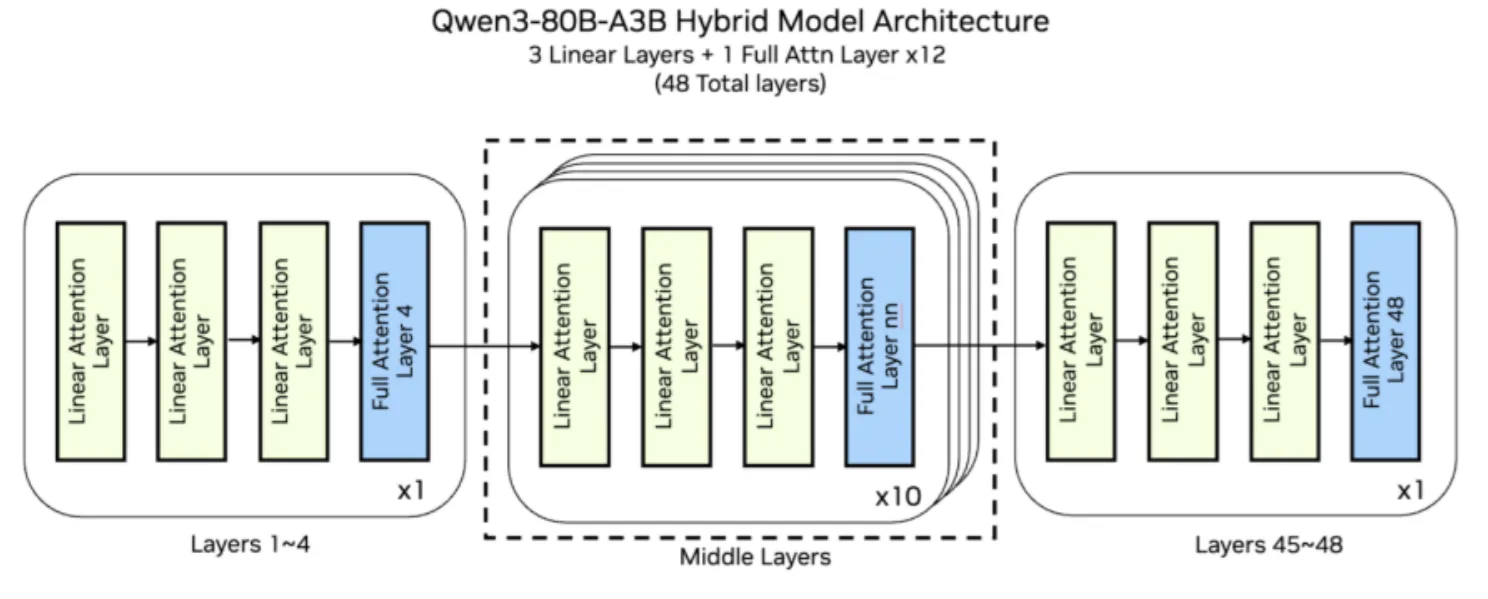
New Open Source Qwen3-Next Models Preview Hybrid MoE Architecture ...
Distributed Parallel Native — MindSpore master documentation
Illustration of data parallelism and model parallelism. | Download ...
how to finetune the mistral-moe with expert/data/pipeline parallel ...
Modulus of elasticity (MOE) in parallel (a) and perpendicular (b ...
Optimizing MoE Parallelism for Efficient Neural Network Training ...
Dynamic MOE (parallel to the grain) measurements results. | Download ...
图解 MoE 模型_自然语言处理_Python蛋挞-2048 AI社区
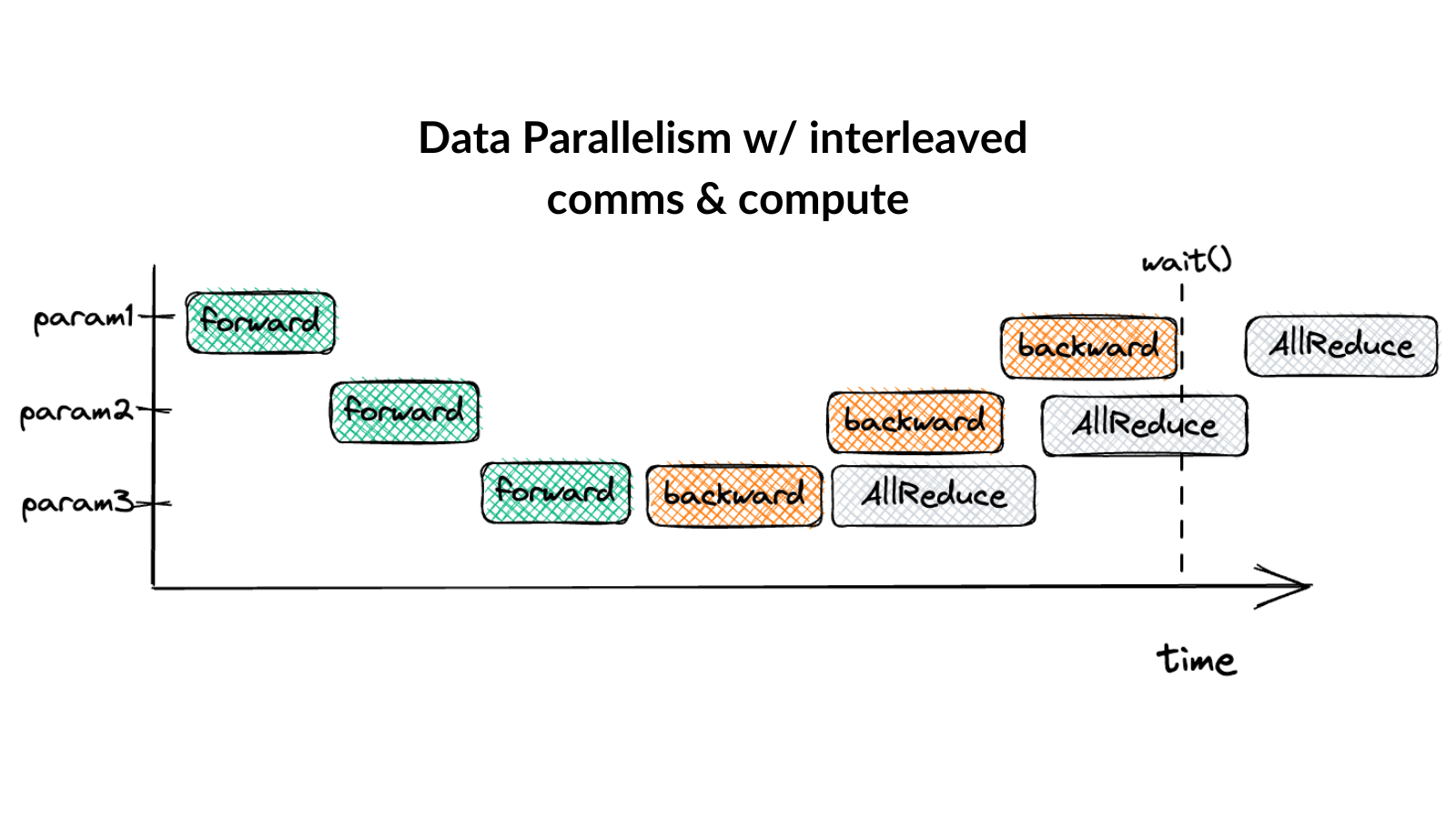
(4/6) AI in Multiple GPUs: Grad Accum & Data Parallelism – Lorenzo ...
(PDF) MOE: A Special-Purpose Parallel Computer for High-Speed, Large ...
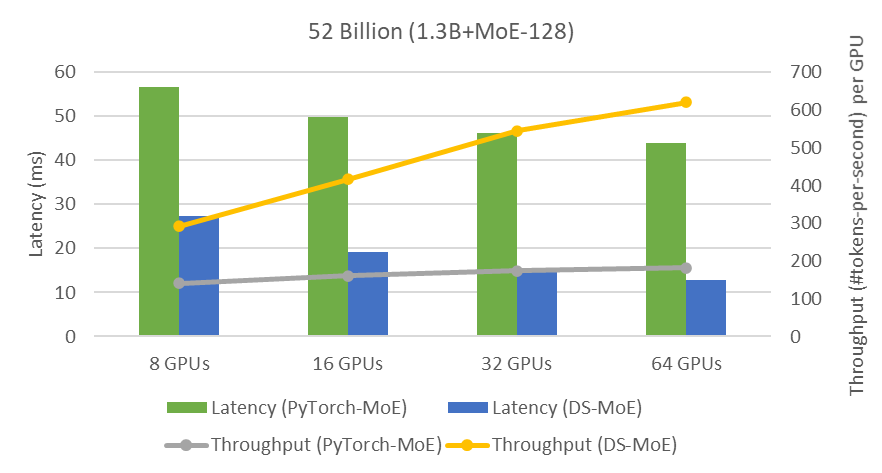
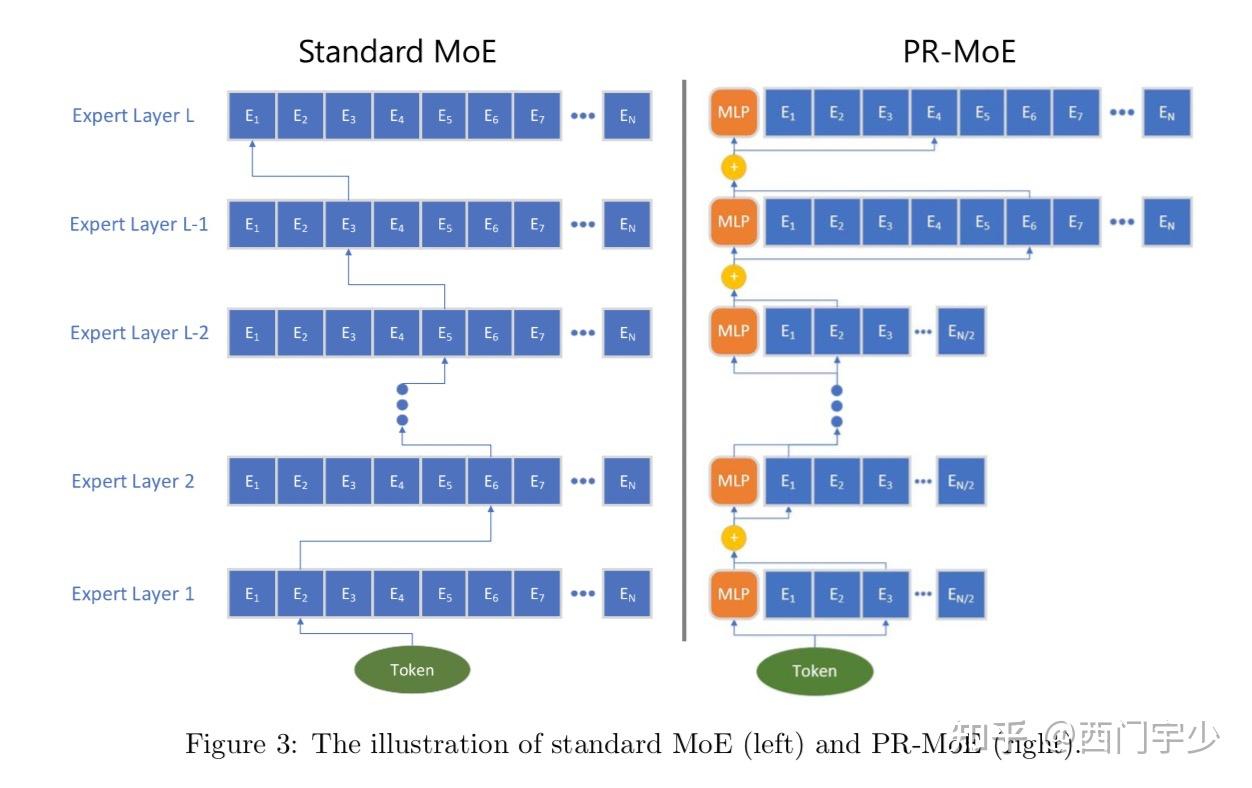
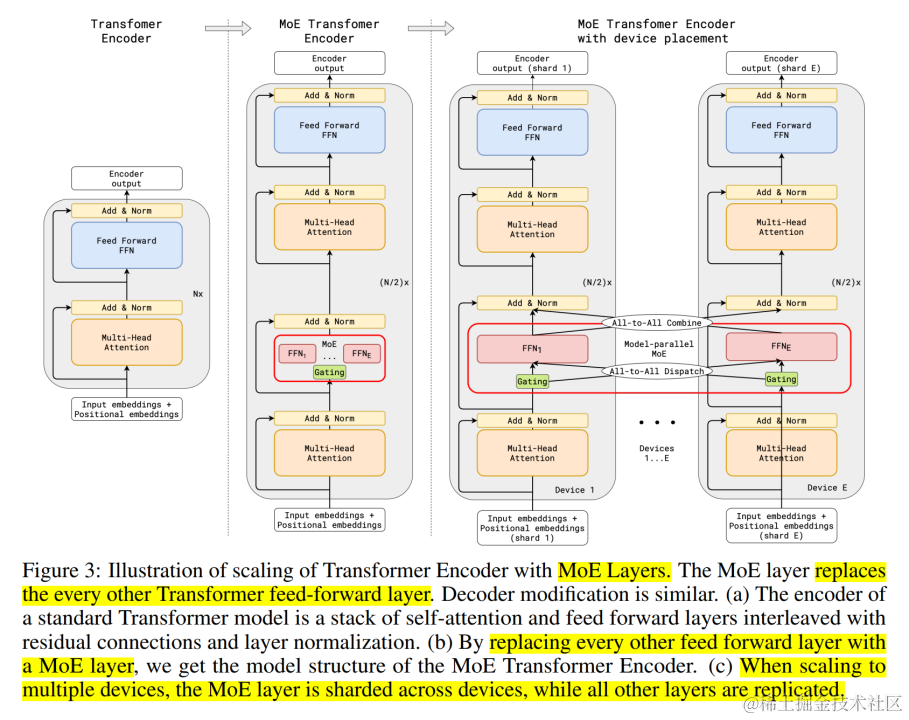
DeepSpeed powers 8x larger MoE model training with high performance ...
Parallel programming model | PPTX
Figure 1 from Prophet: Fine-grained Load Balancing for Parallel ...
Figure 10 from Prophet: Fine-grained Load Balancing for Parallel ...
Plate diagram showing relations between the data and model parameters ...
parallel programming models | PPT
将 MoE 整合进你的模型 | Colossal-AI
Parallel Computing In Machine Learning at Hudson Becher blog
Leveraging Computational Storage for Power-Efficient Distributed Data ...
Getting Started with DeepSpeed-MoE for Inferencing Large-Scale MoE ...
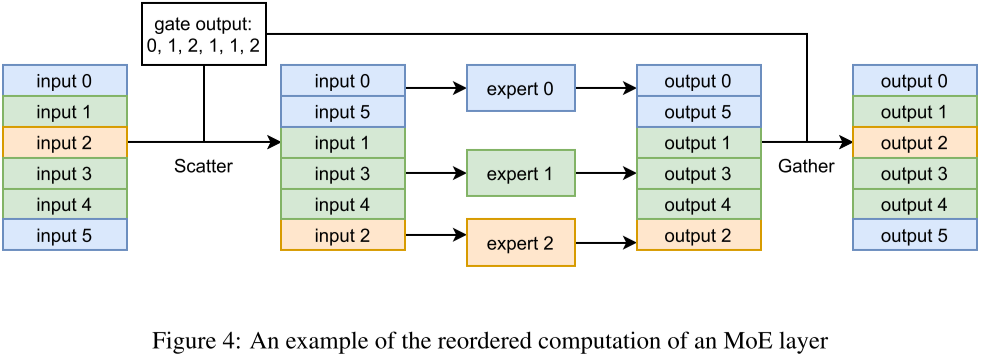
MoE 系列论文解读:Gshard、FastMoE、Tutel、MegaBlocks 等-CSDN博客
MoE in Large Model - 知乎
Training Deep Networks with Data Parallelism in Jax
Data Parallel, Task Parallel, and Agent Actor Architectures – bytewax
Mixture-of-Experts (MoE): ขยายพลัง LLM แบบฉลาดและคุ้มค่า - Big Data ...
MoE 入门介绍 核心工作回顾 模型篇 - 知乎
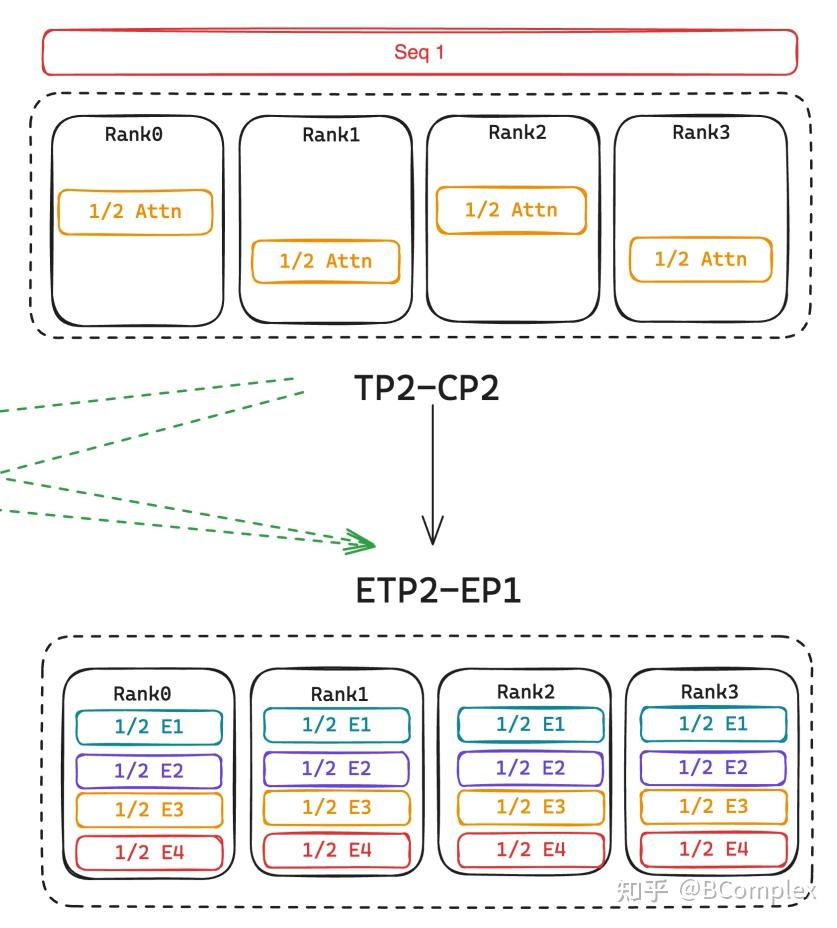
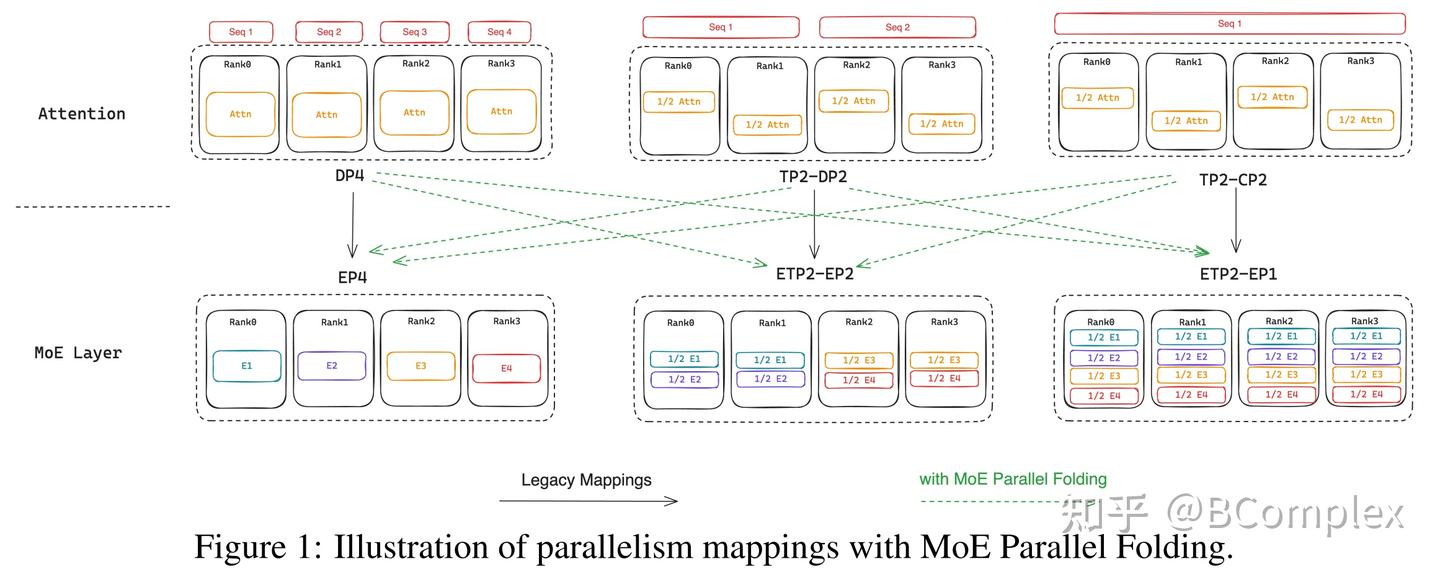
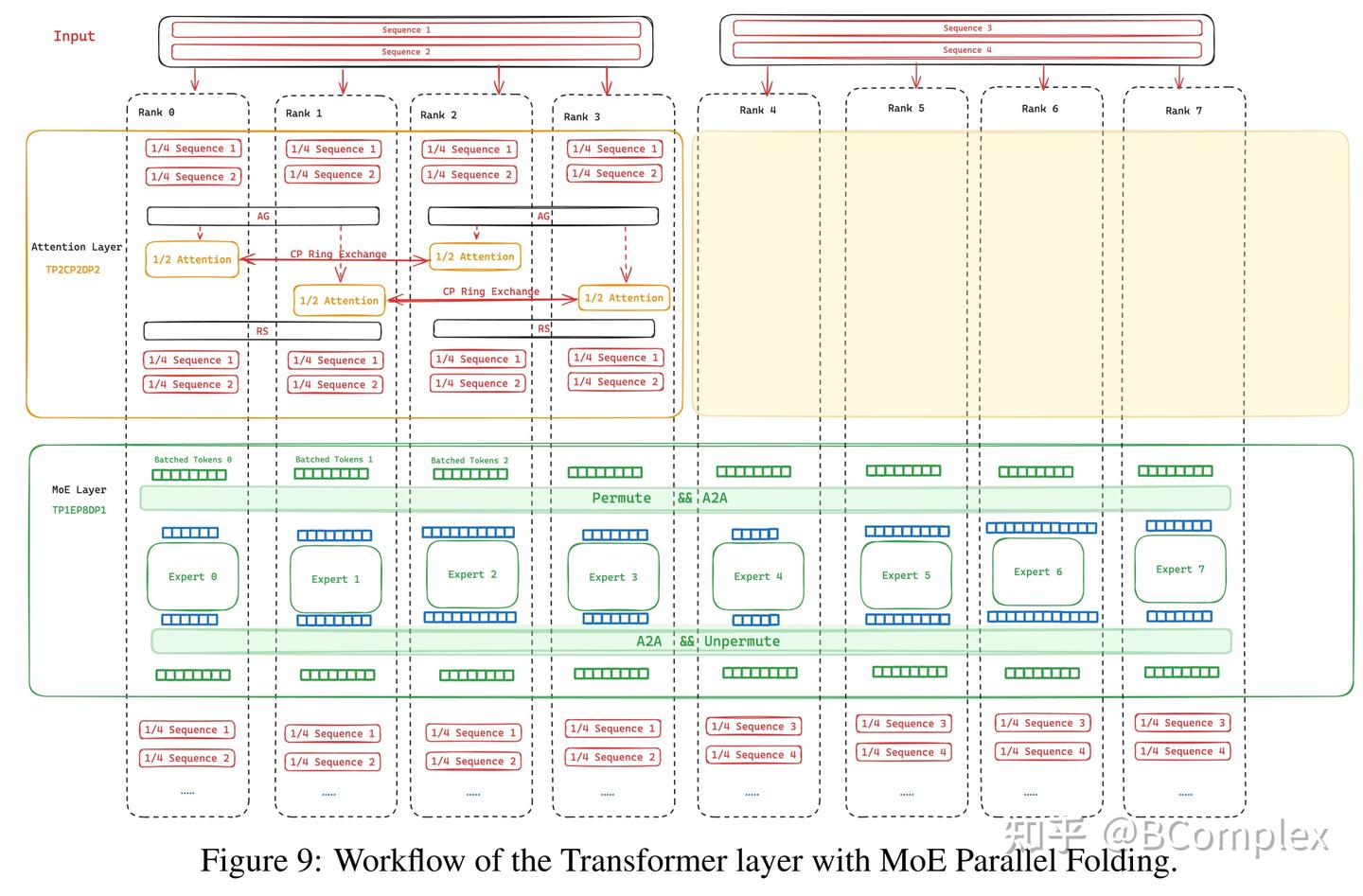
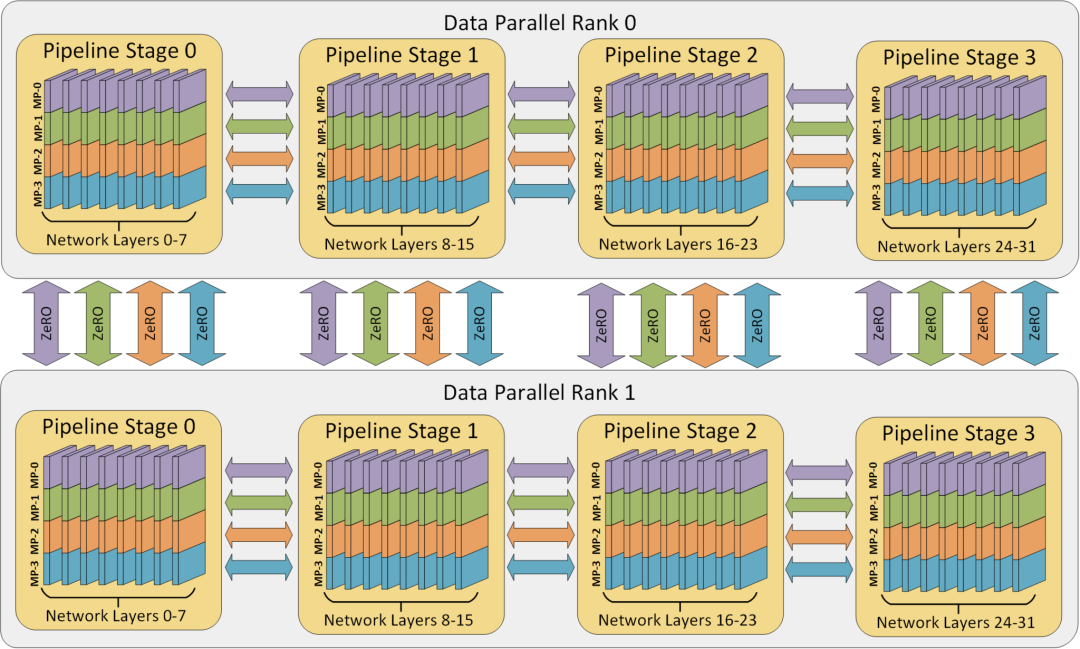
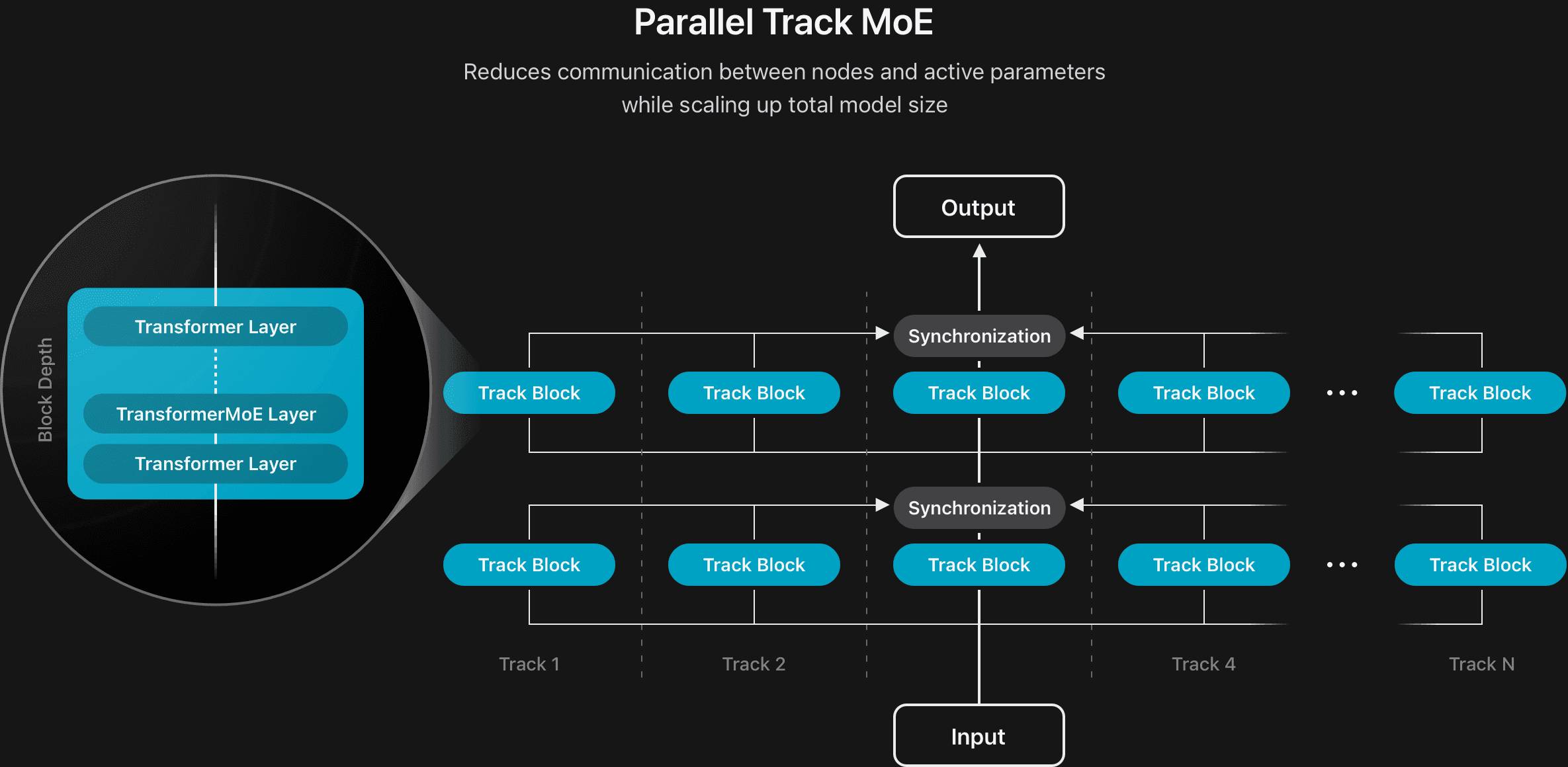
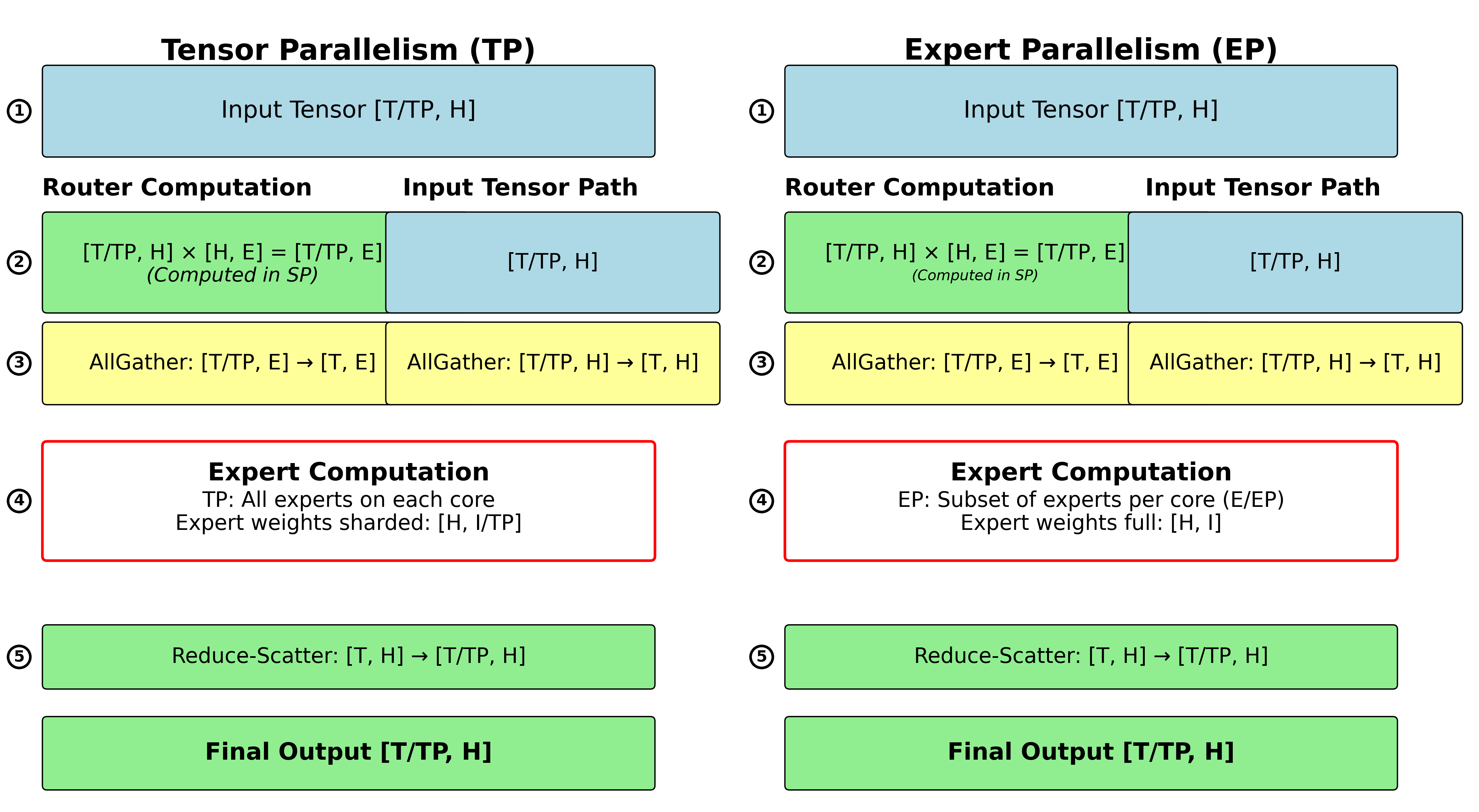
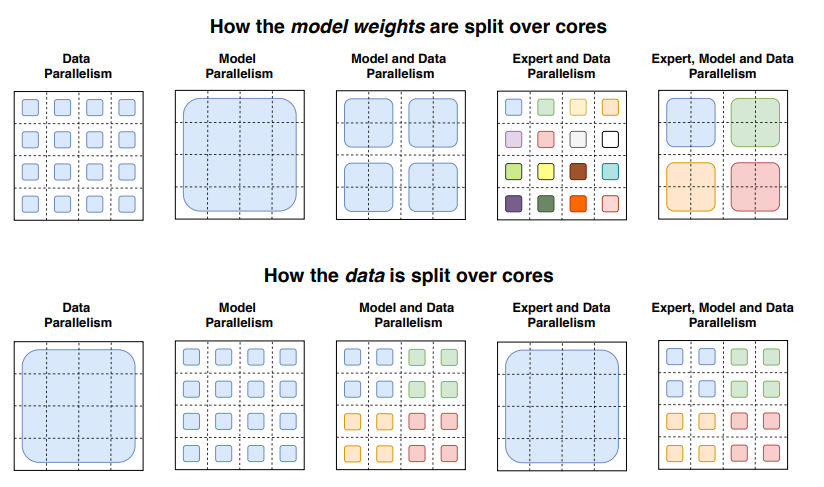
Parallelisms Guide — Megatron Bridge
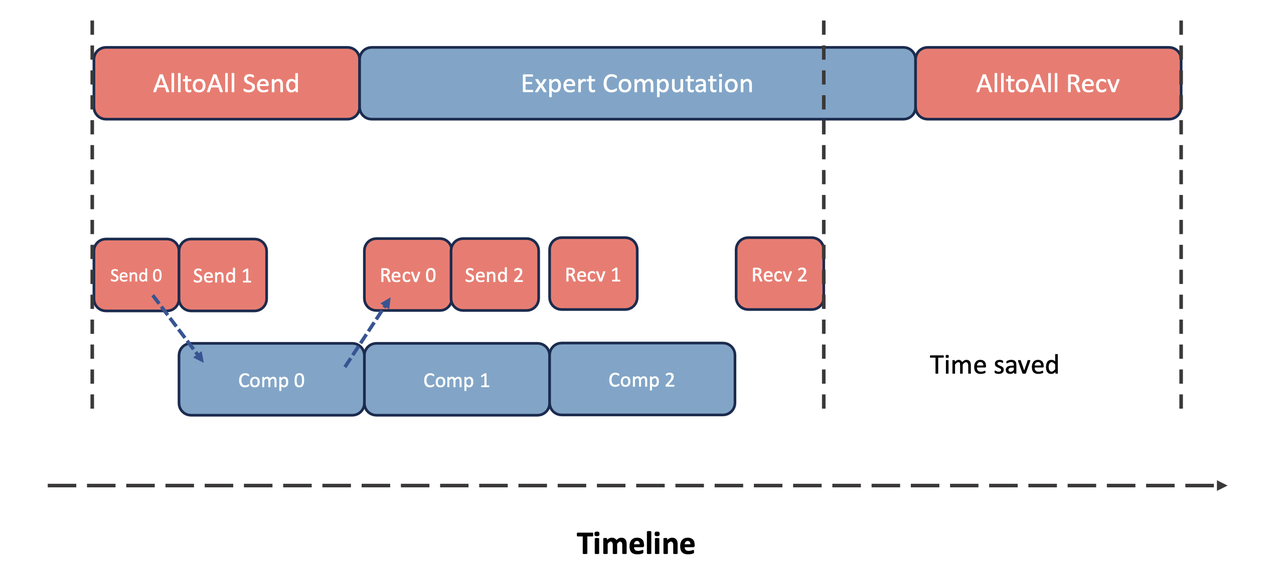
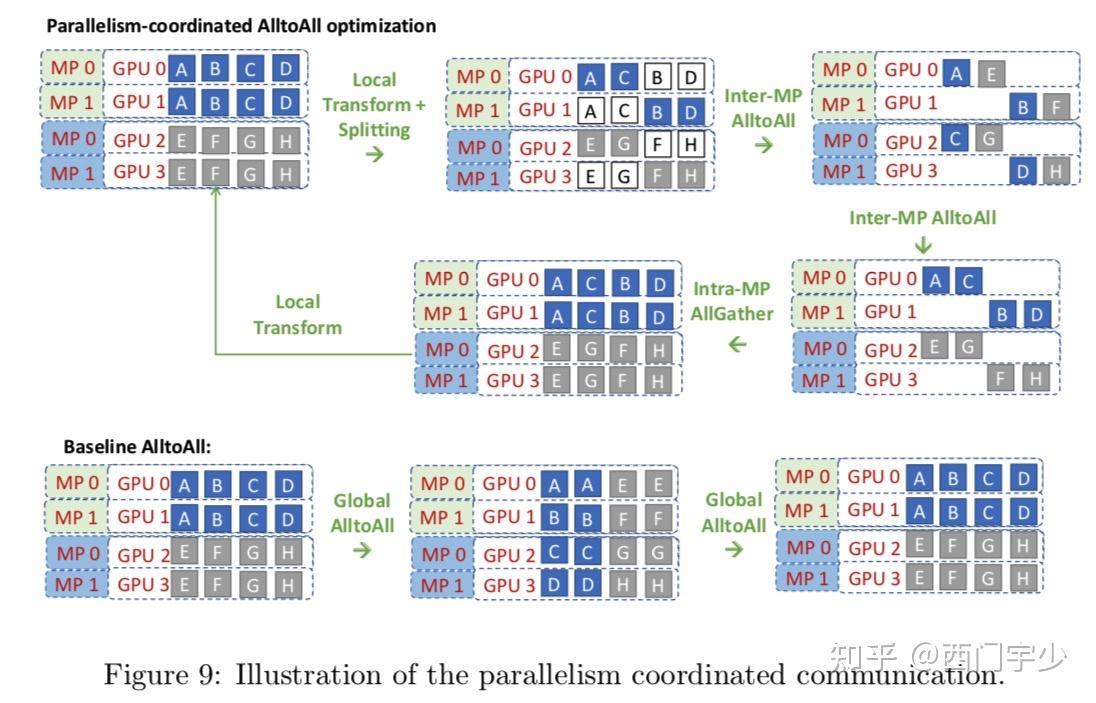
太极AngelPTM MoE组件性能优化策略——Part2_moe alltoall通信原理_腾讯太极机器学习平台的博客-CSDN博客
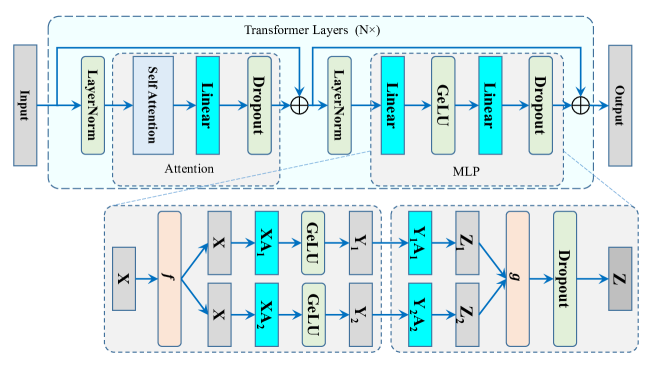
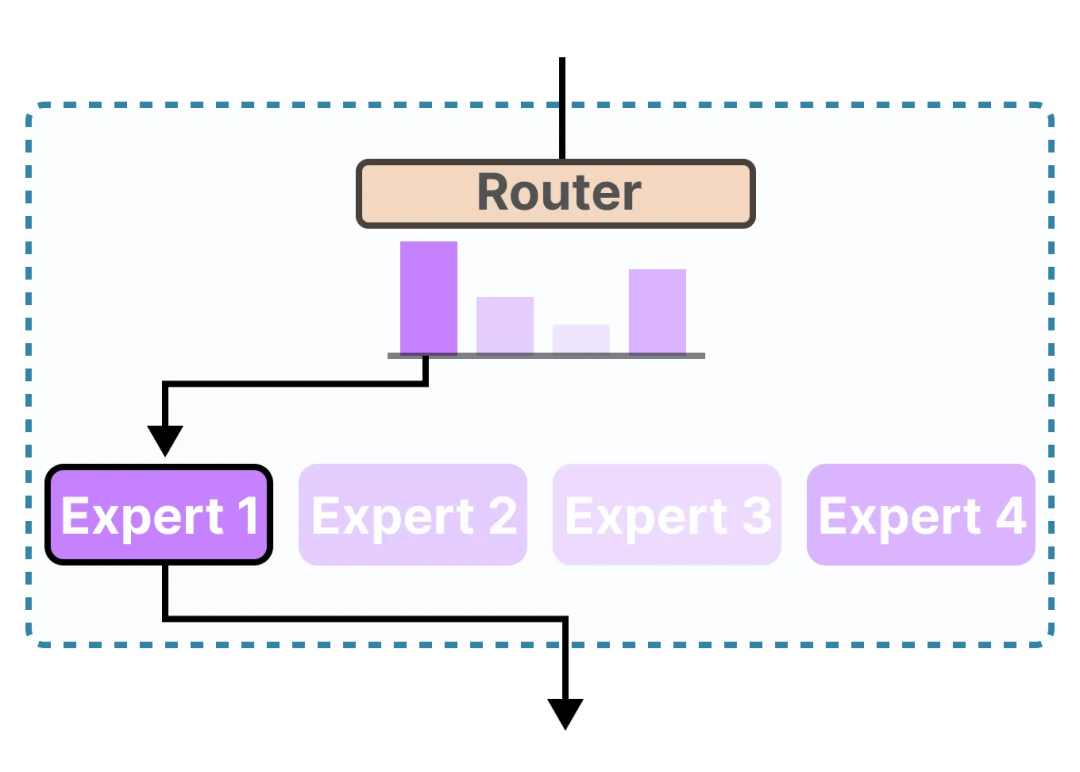
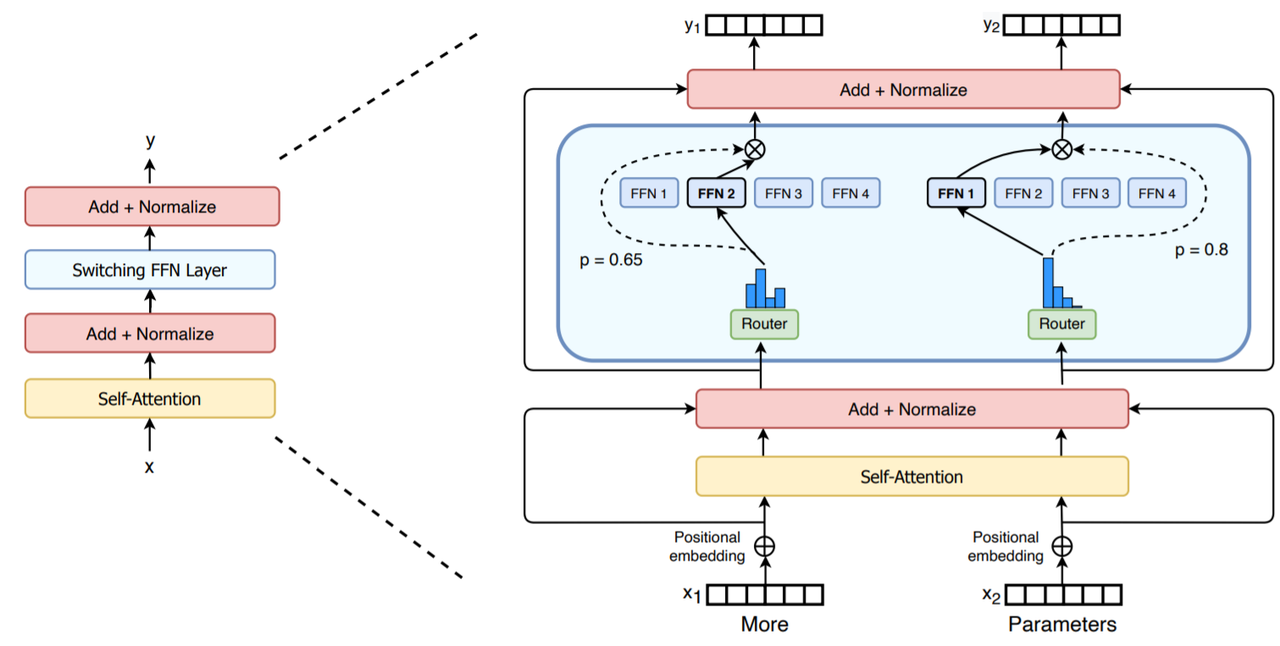
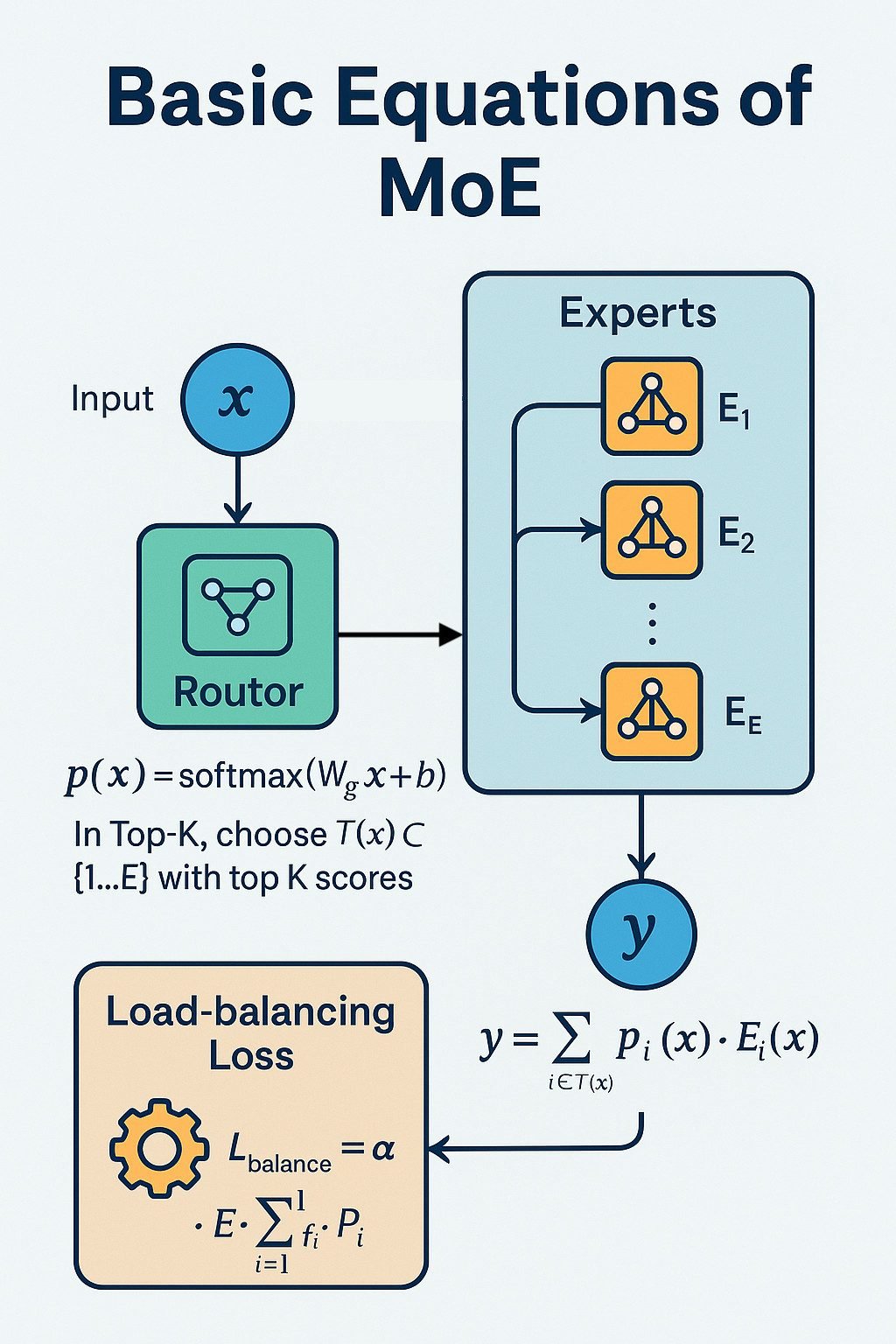
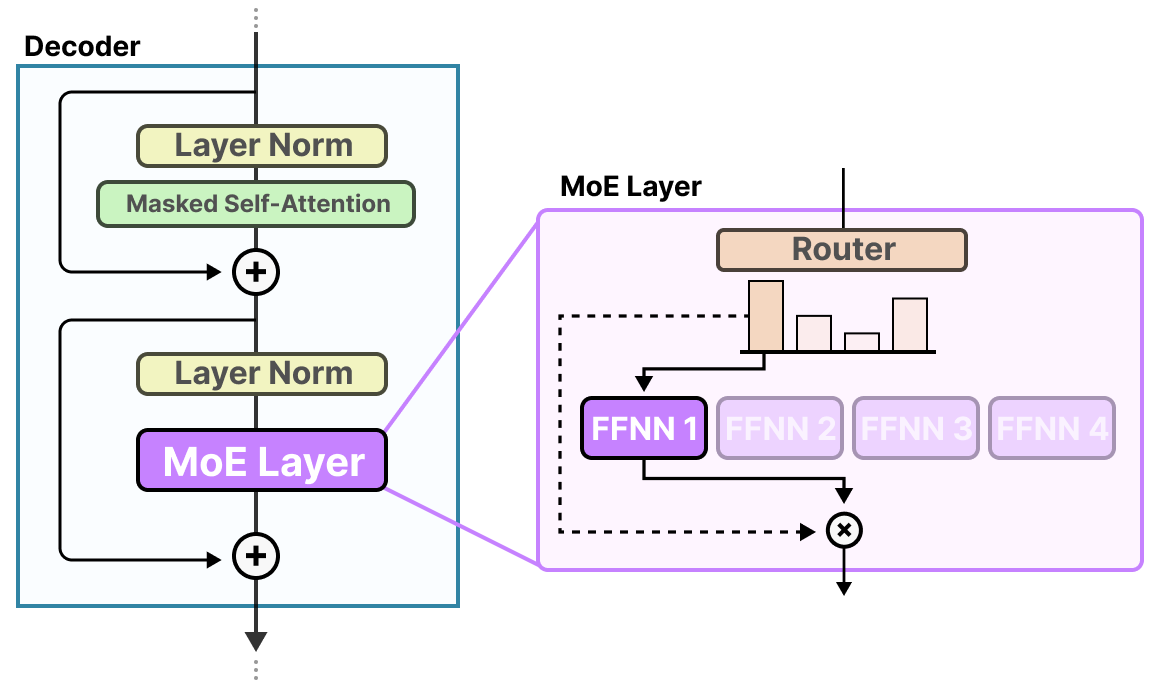
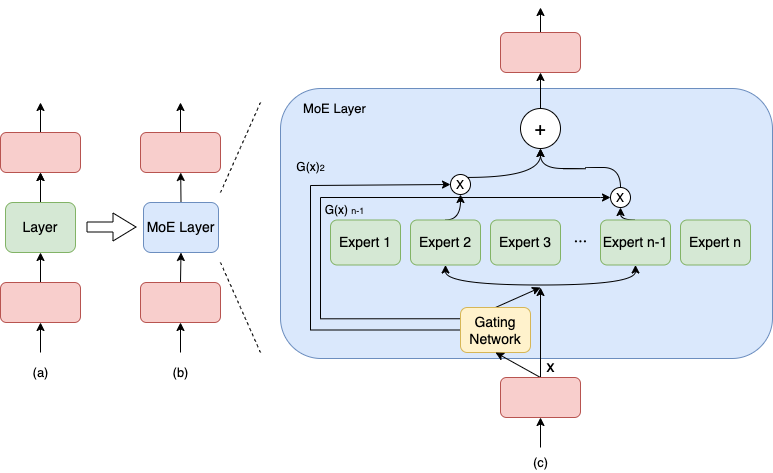
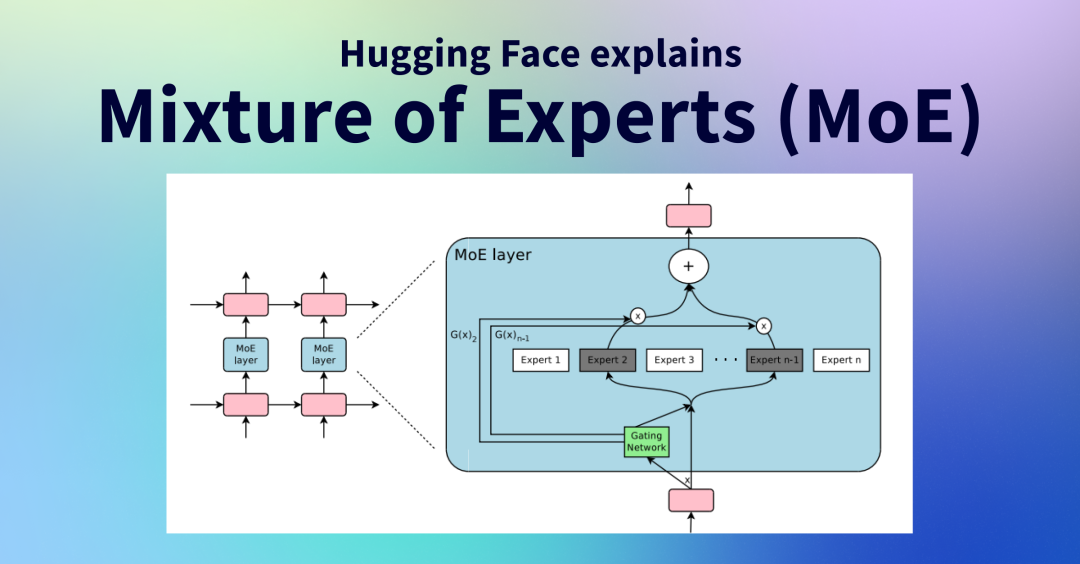
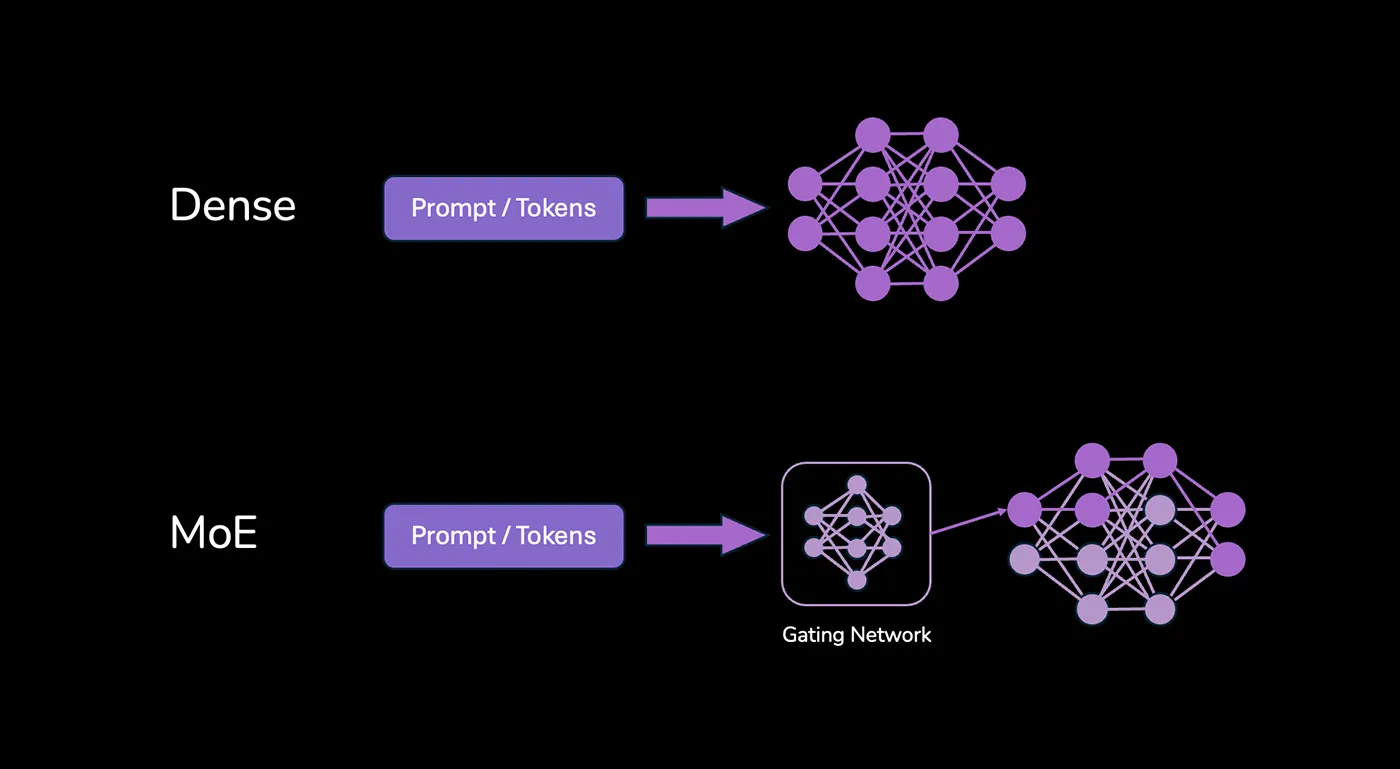
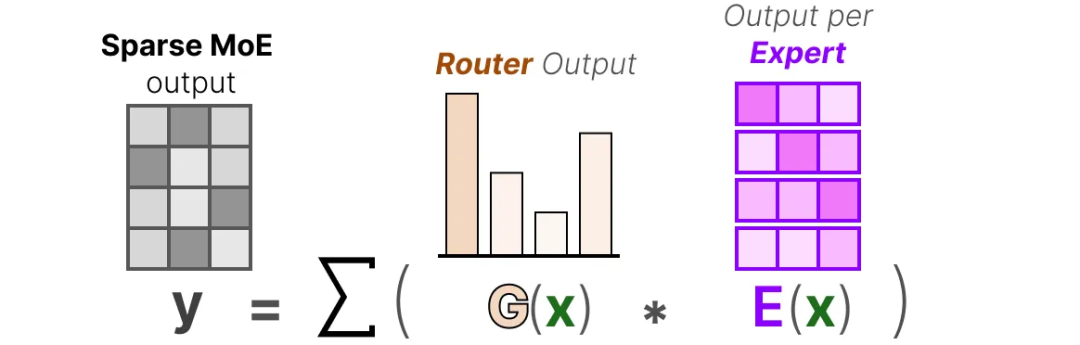
A Visual Guide to Mixture of Experts (MoE)
对MoE大模型的训练和推理做分布式加速——DeepSpeed-MoE论文速读 - 知乎
Apple's new AI benchmarks show its models still lag behind leaders like ...
Deep dive: Explore Mixture of Experts (MoE) inference support for ...
EP Parallelism - xLLM
MoE-使用文档-PaddlePaddle深度学习平台
小白必看:MoE 架构详解(大模型入门指南),一篇搞定!_moe框架-CSDN博客
混合专家模型 (MoE) 详解 - 木子吉 - 博客园
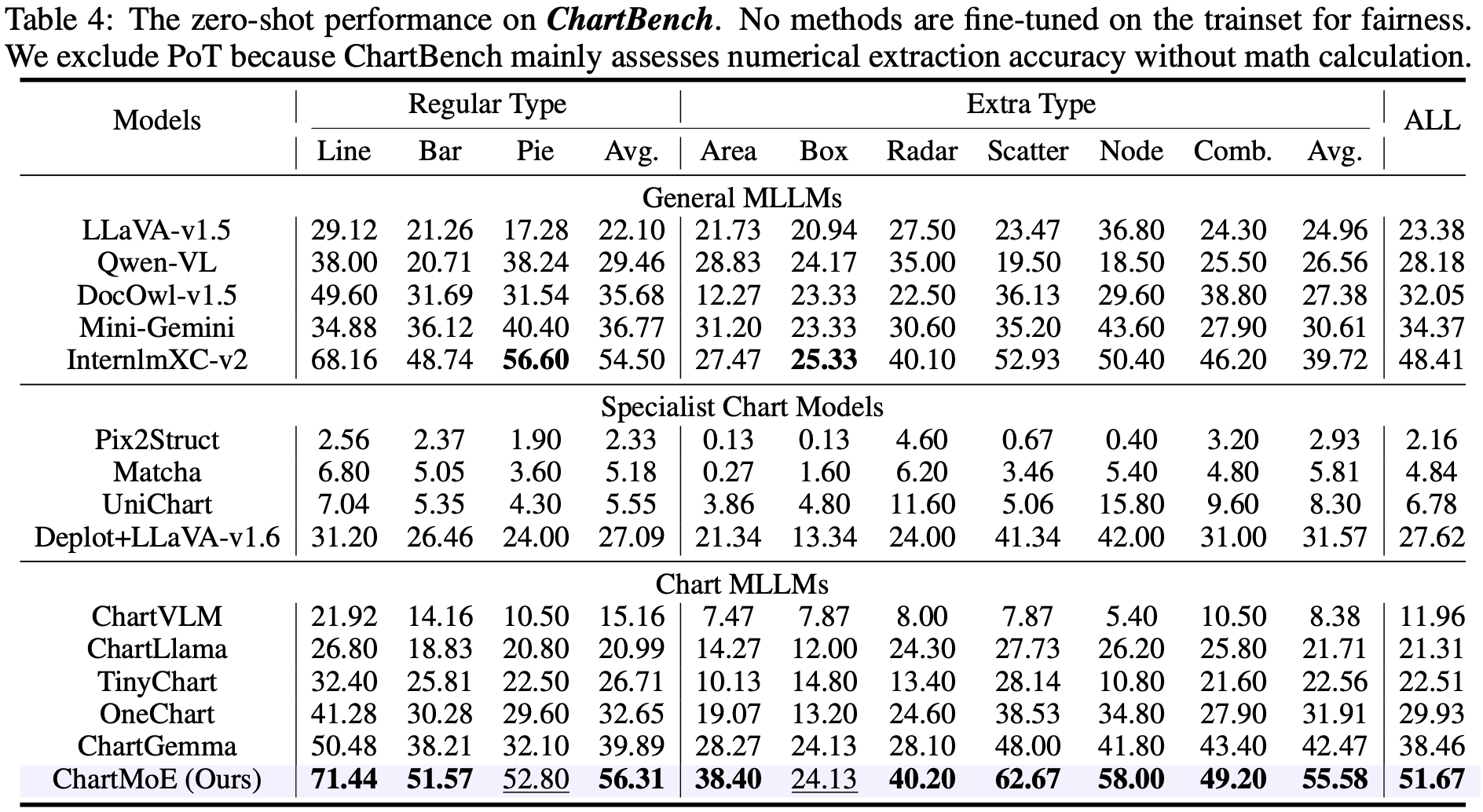
ChartMoE
大模型训练~显卡_llama2 70b 多大内存能推理-CSDN博客
一周前被MoE刷屏?来看看LoRAMoE吧!通过类MoE架构来缓解大模型世界知识遗忘-CSDN博客
PyTorch로 전문가 혼합(MoE) 모델 학습 확장하기 | 파이토치 한국 사용자 모임
Accelerating AI: Implementing Multi-GPU Distributed Training for ...
SmartMoE-CSDN博客
moe-data · GitHub
What Is Mixture of Experts (MoE) in Machine Learning
GitHub - anaykulkarni/moe-model-parallelism: Benchmarking results for ...
一份MoE 可视化指南_v-moe-CSDN博客
Mixture-of-Experts (MoE): The Birth and Rise of Conditional Computation
Mixture of Experts (MoE) vs Dense LLMs
字节砍MoE训练成本,节省数百万GPU小时-腾讯云开发者社区-腾讯云
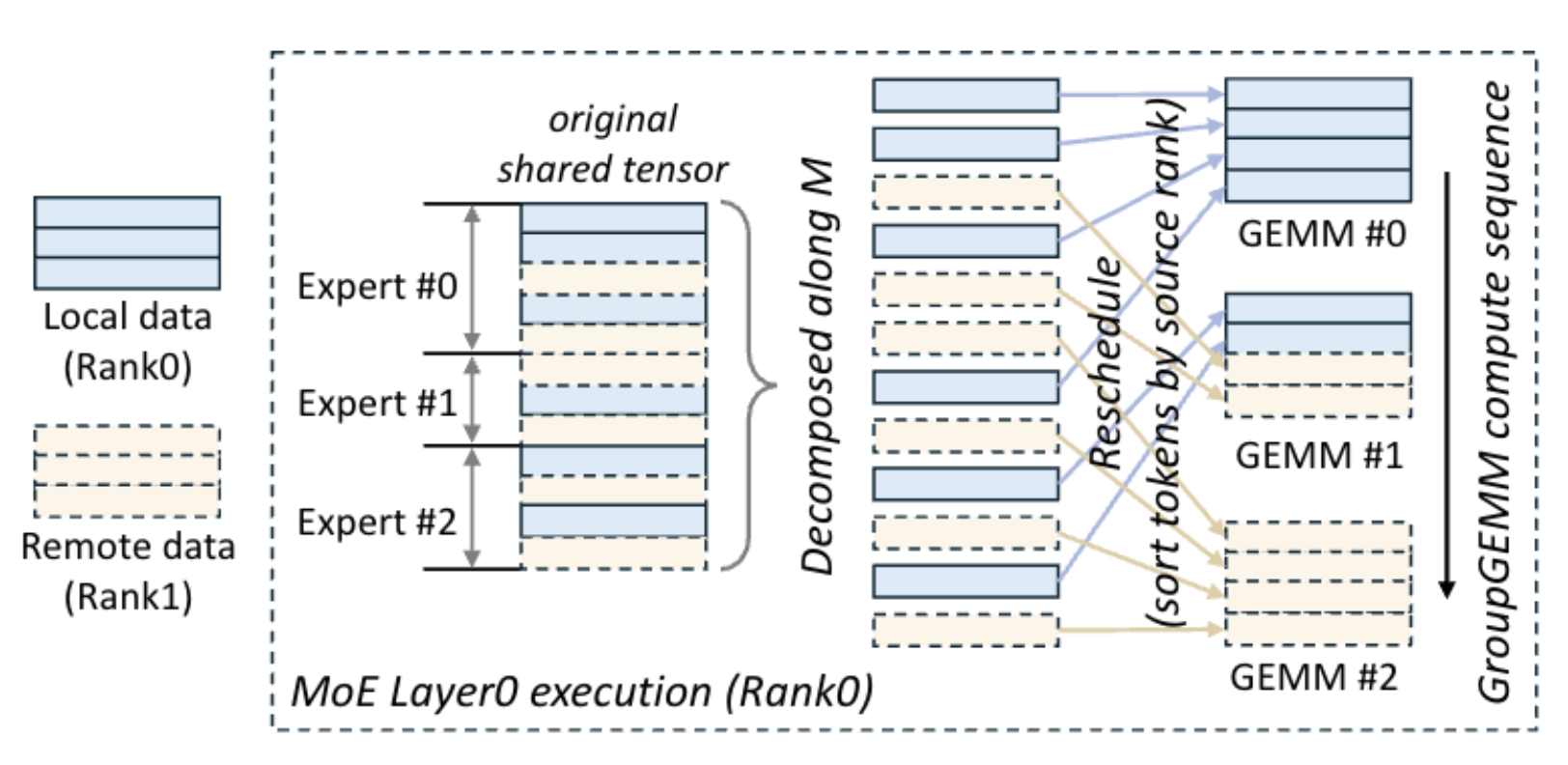
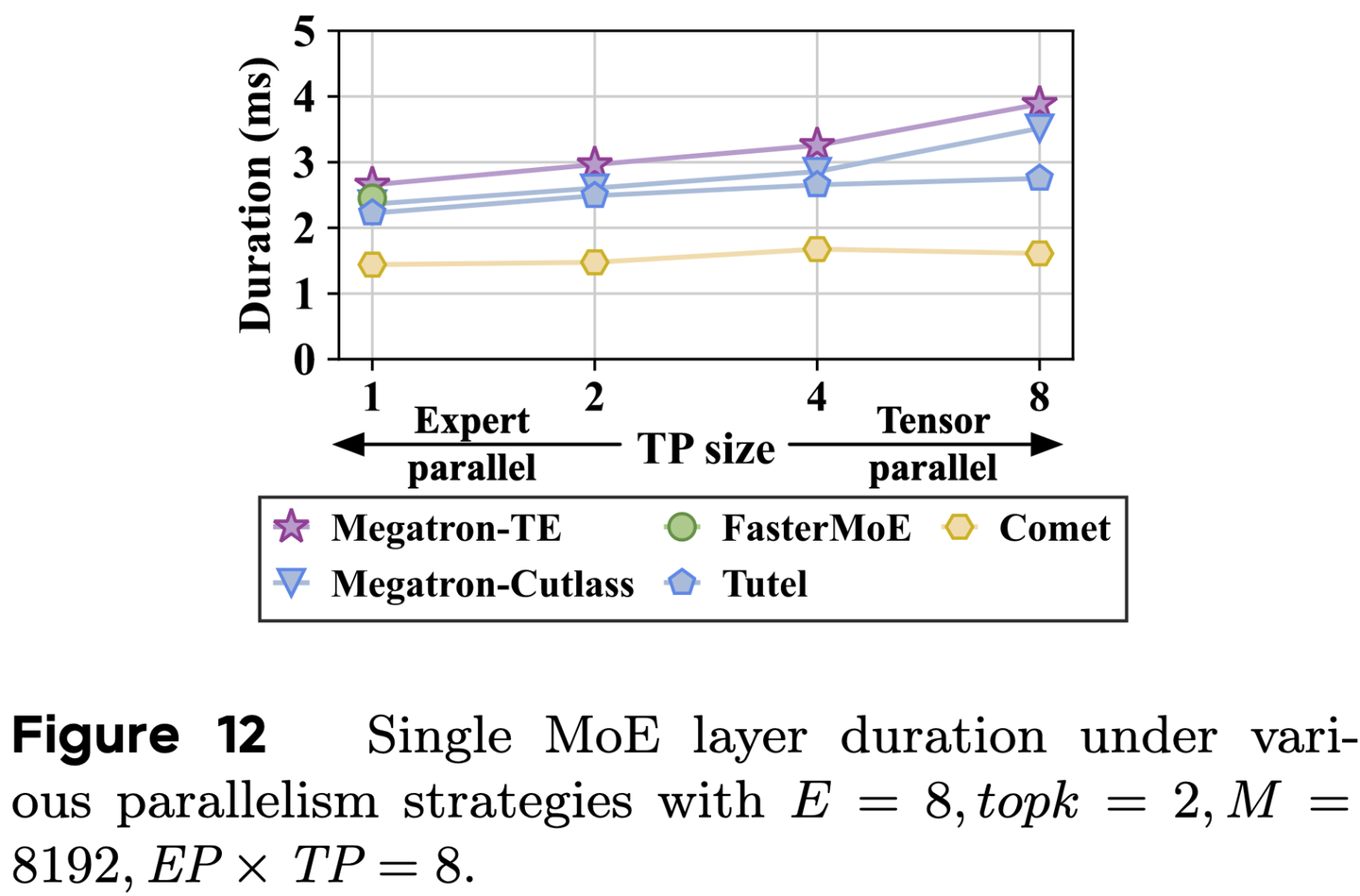
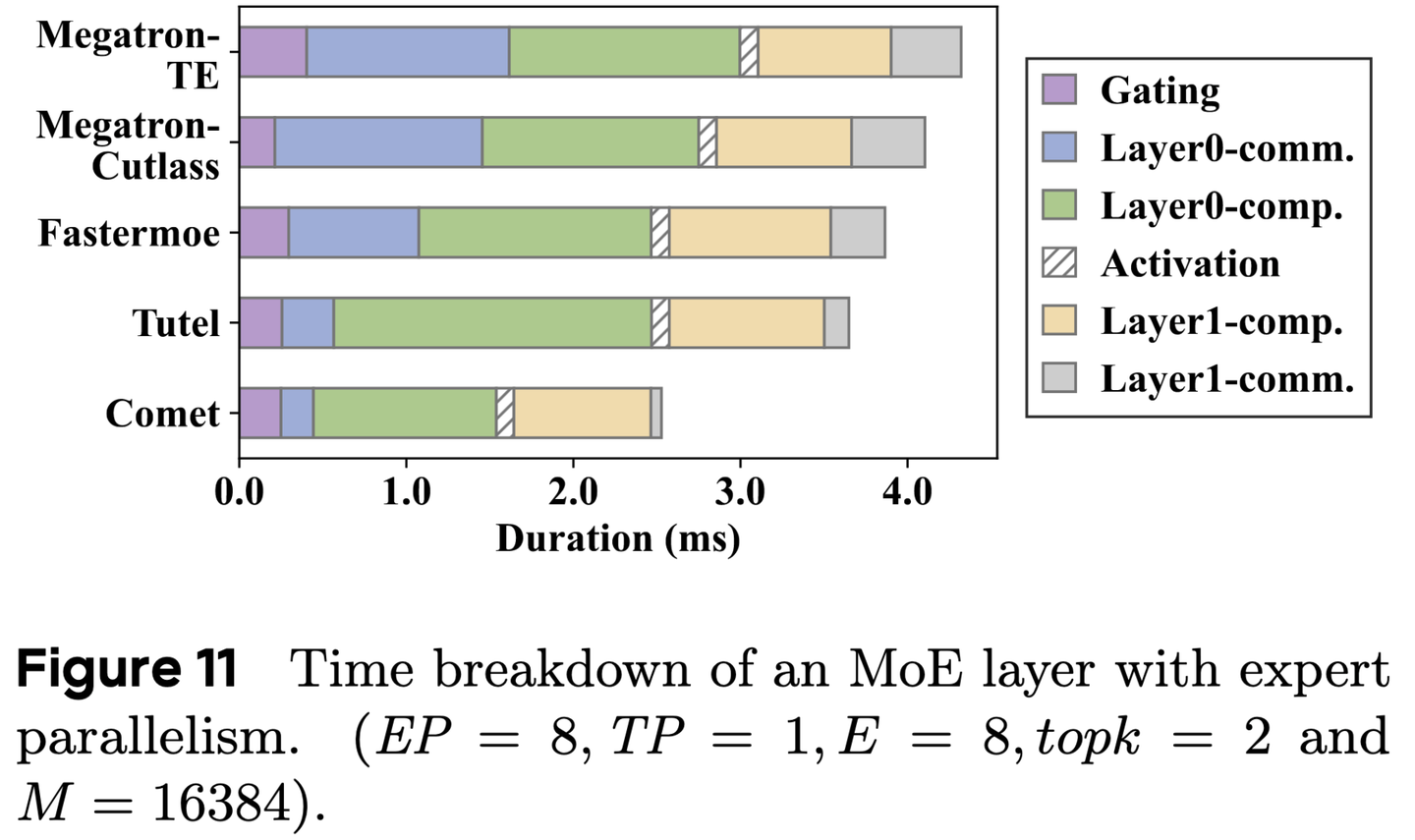
Comet:字节关于大规模MoE通信计算重叠系统 - 知乎
一份MoE 可视化指南-CSDN博客
一文读懂:混合专家模型 (MoE)-deepseek v4 - 知乎
榨干NVLink:三种视角下的Symmetric Memory - 知乎
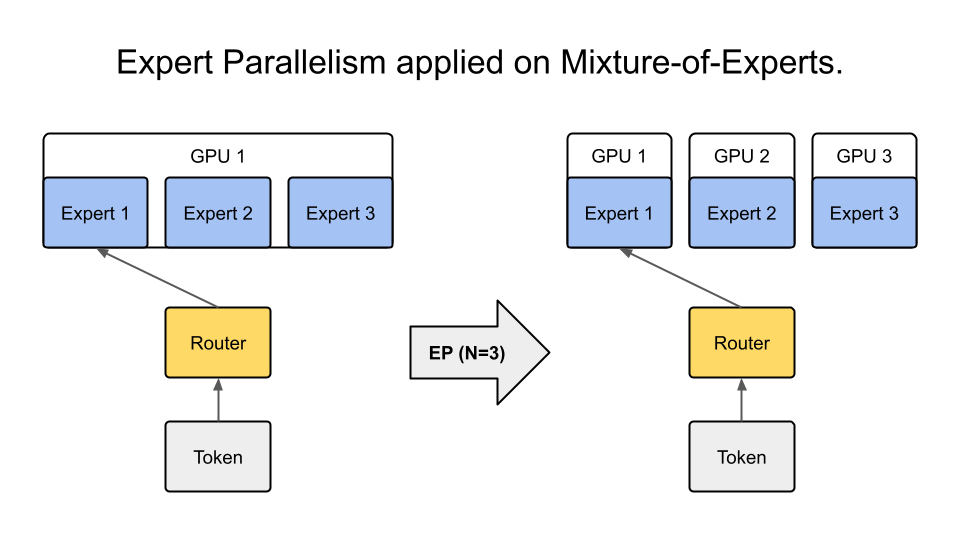
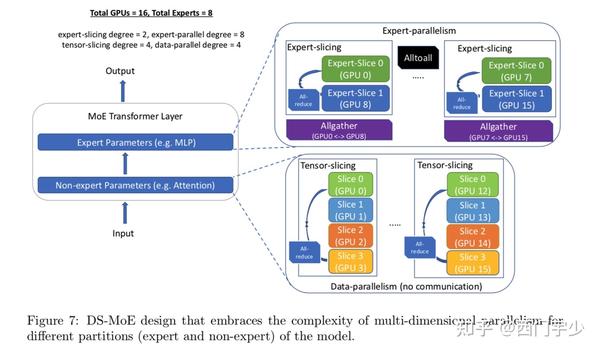
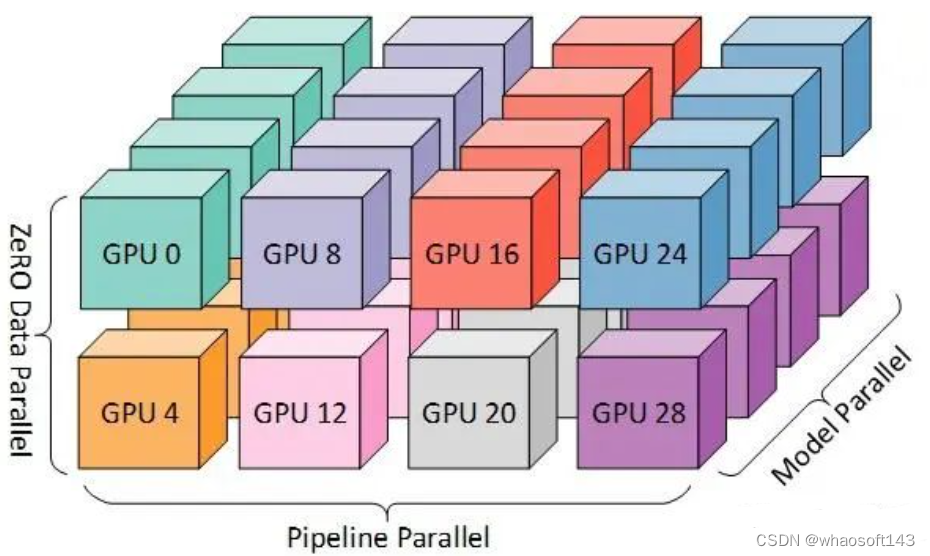
大模型分布式训练并行技术(八)-MOE并行 - 知乎
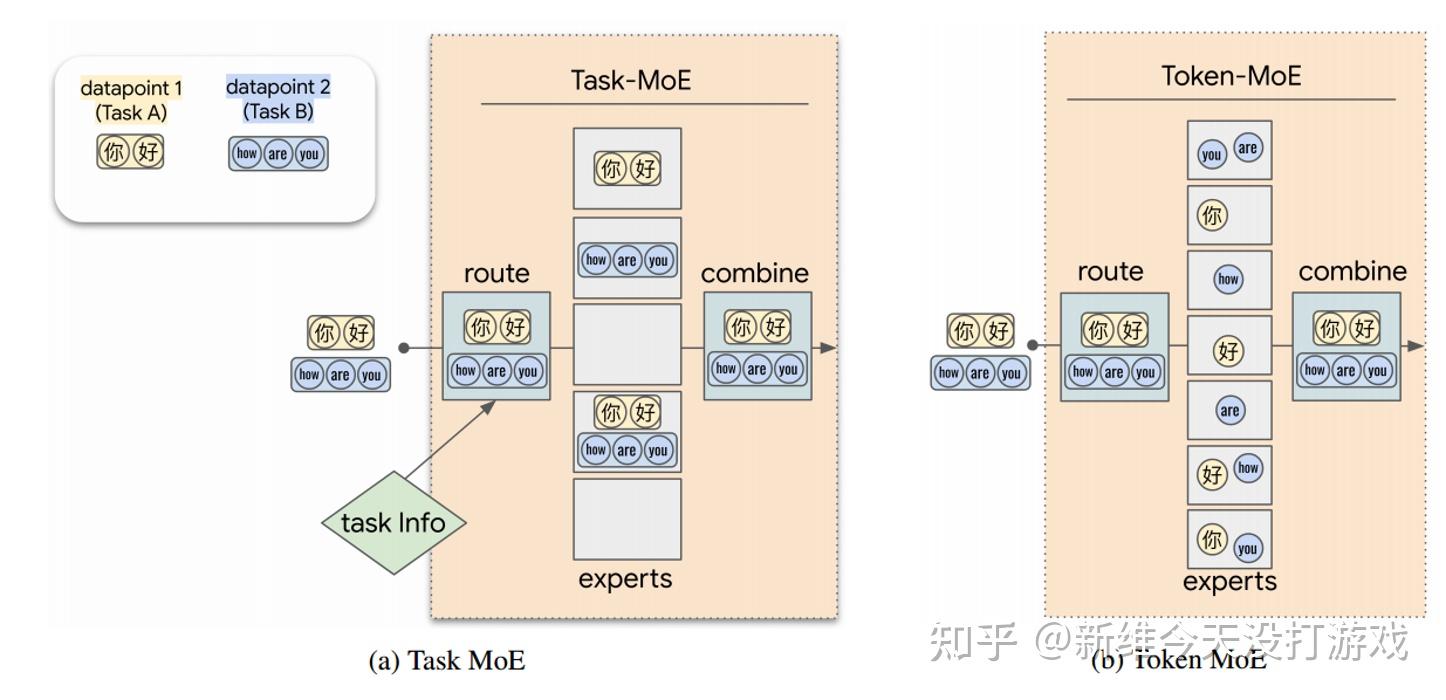
迈向更高效通用的加速之路:谷歌提出视觉和多任务MoE方法
Advanced Image Recognition Powered by DeepSeek R1
[논문 리뷰] Multi-Head LatentMoE and Head Parallel: Communication-Efficient ...
TIME-MOE: Billion-Scale Time Series Foundation Model with Mixture-of ...